金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
假设检验是统计中的一个基本概念,在离散选择模型中也会经常遇到。
每一个统计软件,不论是SAS、STATA还是Biogeme,它们在给出参数估计值的同时,还会对每一个系数做假设检验,并给出相应的检验统计量以及p值——如图1中的红色部分所示。
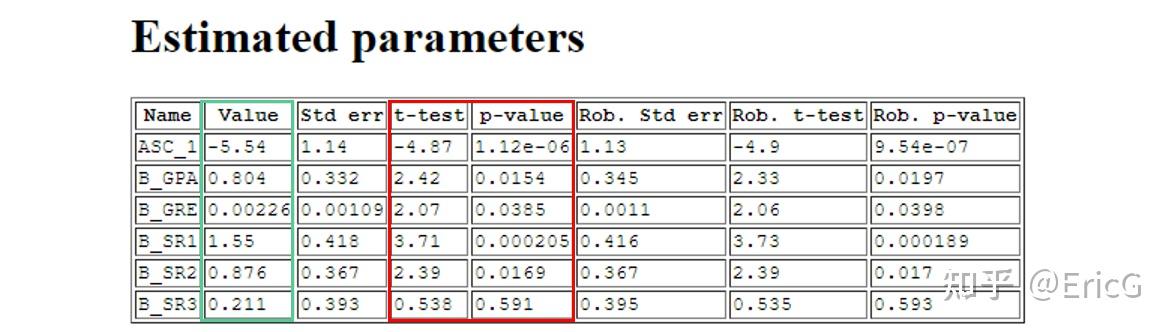
图1:Logit模型参数估计结果示例(Biogeme)
今天咱们就来聊一聊假设检验的基本思想,以及最常见的Z检验和t检验。
女士品茶的故事
1920年的剑桥大学,某个风和日丽的下午,一群科学家正悠闲地享受下午茶时光。正如往常一样准备冲泡奶茶的时候,有位女士突然说:“冲泡的顺序对于奶茶的风味影响很大。先把茶加进牛奶里,与先把牛奶加进茶里,这两种冲泡方式所泡出的奶茶口味截然不同。我可以轻松地辨别出来。”在场的绝大多数人对这位女士的“胡言乱语”嗤之以鼻。然而,其中一位身材矮小、戴着厚眼镜的先生却不这么看,他对这个问题很有兴趣。这个人就是费歇尔(R. A. Fisher)。

R. A. Fisher
Fisher的思路是:他首先假该设女士没有这个能力(这个假设被称为原假设H_0)。随后,Fisher将8杯已经调制好的奶茶随机地放到那位女士的面前,看看这位女士能否正确地品尝出不同的茶。
用字母 p 表示该女士每次答对的概率,用随机变量 X 表示女士答对的次数;在 n 次实验中,女士答对 k 次的概率可以用二项分布来描述:
P(X=k) = C^{k}_{n} p^k (1-p)^{n-k} \;\;\;\; (1) \\
在原假设下,女士并没有鉴别的能力,能否答对完全靠蒙——此时,p=0.5(类似于抛硬币)。
利用(1)式,我们可以计算出 n=8、p=0.5时女士答对 k 次的概率,如下图2所示:
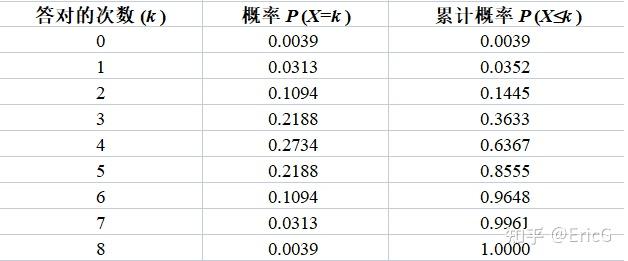
图2:n=8、p=0.5时女士答对 k 次的概率
现在问题来了:如果实际观测到女士连续答对了8次(即k=8),那么,她到底有没有鉴别能力?或者,从概率的角度来看:原假设 p=0.5 到底对不对?
继续阅读之前,建议各位看官先自行思考一下...

从图2中可以看出:如果原假设 p=0.5 成立(即女士没有鉴别能力),那么99.61%的情况下,女士蒙对的次数应该小于或者等于7次。
而现在实际观测到的结果是女士连续答对了8次——这说明了什么?当 p=0.5 时,“连续答对8次”的概率比较低,仅为 0.39%;而只有当 p 大于0.5 大于时(比如,接近于1),发生“连续答对8次”这种事情的概率才比较高。也就是说,女士极有可能具备鉴别能力。在一次观测中,当小概率事件发生时,我们有足够的理由怀疑原假设 (p=0.5) 的正确性。
有人可能会问:如果该女士确实没有鉴别能力,而仅仅是那天运气比较好、连续蒙对了8次——有没有这种可能?
有这种可能。虽然本例种发生这种情况的概率比较小,仅为0.39%。
这就意味着:我们的判断有可能是错误的。如果女士确实没有鉴别能力(原假设为真),而我们根据观测到的样本做出了“拒绝原假设”的判断——那我们就犯了第I类错误。
引入第I类错误和第II类错误的概念:
- 第I类错误也叫弃真错误或α错误:它是指 原假设实际上是真的,但通过样本估计总体后,拒绝了原假设。这个错误的概率我们记为α。
- 第II类错误也叫取伪错误或β错误:它是指 原假设实际上假的,但通过样本估计总体后,接受了原假设。这个错误的概率我们记为β。
回到上面的例子:我们犯第I类错误的概率 α=0.39%。
类似地:如果我们观测到女士答对的概率大于或者等于7次(k\ge7),我们依然有很大的把握拒绝原假设。此时,我们犯第I类错误的概率 α=3.52% (1-96.48%)。
继续这个问题:如果我们观测到女士答对的概率小于或者等于4次(k\le7),那么,我们还能拒绝原假设吗?——这时我们会接受原假设。因此此时如果选择拒绝原假设,我们犯第I类错误的概率α=36.33% (1-63.67%)。相对k\ge7或者k=8的情形,此时,我们犯第I类错误的风险已经增加了很多。
当我们对原假设H_0是否为真作出判断时有可能会犯错误,这就是要冒风险;为了控制这一风险,首先需要用一个概率去表示这一风险,这个概率便是“H_0为真但被拒绝”的概率,这个概率又称为显著性水平,记为α:
P(H_0被拒绝|H_0为真) \le \alpha \\
为了控制犯第I类错误的概率,一般在假设检验之前就会规定好α的大小。在上面的例子中,如果规定α=0.05,我们只有观测到k\ge7时才会拒绝原假设(此时犯第I类错误的概率0.035规定的值0.05);如果规定α=0.01,我们只有观测到k=8时才会拒绝原假设(此时犯第I类错误的概率0.0039规定的值0.01)。
字面上看,假设检验(hypothesis testing)由“假设”和“检验”组成。假设是关于总体某个性质的假设(比如全国成年男性的平均身高,某新型药品是否有效,等等),而检验在样本上完成的。所谓假设检验,就是通过样本来推测总体是否具备某种性质。
上例中,Fisher通过一组实验获得了一个样本;如果他重新再做一次实验,便会获得另外一组样本。Fisher要推断的总体的性质是:女士是否拥有鉴别“先加奶”还是“先加茶”的能力。
在离散选择模型中也是如此。我们通过问卷调查,或者实地观测,获得一组样本数据;然后通过拟合得到参数的估计值 \hat{\beta}。一般情况下,我们感兴趣的是:总体所对应的 \beta 是否等于0(或者某个已知的值)。
样本 vs 总体
总体是研究对象的整个群体;样本是从总体中选取的一部分。
假设我们通过抽样调查获得一组数据,然后据此拟合得到某个参数的估计值 \hat{\beta_{i}}=0.211。那么,我们能否认为总体所对应的参数 \beta_{i} 一定等于0.211呢?
不一定。如果我们再次抽样、然后拟合,很有可能得到另一个估计值。
一方面,样本继承了总体的某些性质,我们可以利用样本推断总体的某些性质;另一方面,样本只是总体的一部分,它不等同于总体。样本与总体直接的区别称之为抽样误差(Sampling Error)。由于抽样误差的存在,当我们利用样本推断总体的性质时,总会有犯错的风险。
原假设 vs 备择假设
假设检验中包含两个相互排斥的假设,分别称为原假设(H_0)和备择假设(H_1)。
原假设一般是统计者想要拒绝的假设,而备则假设是统计者想要接受的假设。
例如,当我们比较两个总体的均值(\mu_{1}、\mu_{2})时,原假设一般设置为:\mu_{1}=\mu_{2};即,两个总体的均值相等。
在离散选择模型中,我们要验证某个变量(比如收入)是否对选择行为产生影响时,所采用的原假设一般为 \beta_{收入}=0(\beta_{收入}为变量收入对应的系数);即,决策者的收入对选择结果没有影响。
为什么把要拒绝的假设作为原假设?在假设检验中,我们对原假设是比较宽容的:如果样本中的证据不够充分,我们会选择接受原假设。只有当样本中出现了足够强的证据时,我们才会推翻/拒绝原假设。此时,当我们选择拒绝原假设时,只会犯第I类错误:
| 原假设 | 动作 | 后果 | | H0为真 | 拒绝 | 犯第I类错误 | | H0为假 | 接受 |
而犯第I类错误的概率(即 \alpha)在假设检验之前就已经规定好。如果规定\alpha=0.05,那么犯第I类错误的概率:
P(H_0被拒绝|H_0为真) \le 0.05 \\
检验统计量
样本中提供了一定的信息(证据),可以用于判断原假设是否成立。
为方便判断,一般需要对这些证据进行加工处理,得到一个综合指标,然后将该指标与事先选好的阈值进行对比。这个综合了样本信息的指标便称为检验统计量。
看第二个例子。
某车间用一台包装机包装葡萄糖。已知每袋糖的净重是一个随机变量,且服从标准差为 0.015 kg 的正态分布。某日随机抽取它所包装的9袋糖,称得净重为(kg):
0.497, \; 0.506,\; 0.518,\; 0.524,\; 0.498,\; 0.511,\; 0.520,\; 0.515,\; 0.512 \\
问每袋糖的净重的均值 \mu 是否为0.5 kg?
本例中,相应的原假设和备择假设分别为:
H_0: \mu=\mu_{0}=0.5 \\H_1: \mu \ne \mu_{0} \\
由于这里涉及总体均值 \mu 的假设检验,故首先想到的是能否借助样本中提供的信息进行判断。
样本中包含了9个观察值;我们并不会直接用这9个观察值去判断原假设 H_0 是否成立,而是先计算样本的均值 \overline{X}。这是因为,样本均值 \overline{X} 是总体均值 \mu 的无偏估计,\overline{X} 的观察值 \overline{x} 的大小在一定程度上反应了 \mu 的大小。如果H_0为真,则观察值 \overline{x} 与 \mu_{0} 的偏差 |\overline{x}-\mu_{0}| 一般不应太大。若 |\overline{x}-\mu_{0}| 过大,我们就有理由怀疑H_0的正确性而拒绝H_0。
此外,考虑到当H_0为真时,\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \sim N(0,1)。因此,也可以用 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} 的大小衡量 |\overline{x}-\mu_{0}| 的大小。
\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} 即为一个检验统计量。
下一步,适当选定一个阈值 k (k\ge0) ,作为判断标准;当 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \ge k 时就拒绝 H_0;反之,若\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} < k,则接受H_0。
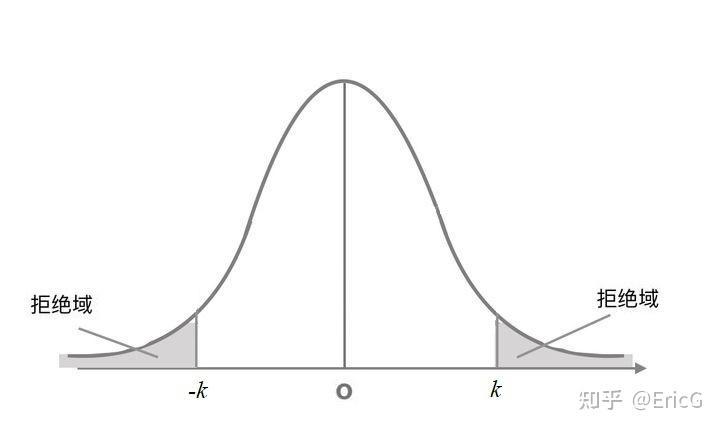
图3:双侧检验拒绝域
从上面的例子可以看出,\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}}是通过对样本观测值做了一定处理得到的;通过这种处理,可以方便地将其跟标准正态分布 N(0,1) 的分位点进行比较,从而得出接受(或者拒绝)原假设的结论。
显著性水平 \alpha
当我们根据样本中的观测值,计算出检验统计量\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}}之后,下一个问题便是:如何选取阈值 k 呢?
从女士品茶的例子中可以看出,阈值 k 的大小是由控制犯第I类错误的概率 \alpha 决定的。若设定\alpha=0.05 ,我们只有观测到“女士答对7次或者7次以上”时,才会拒绝原假设;若设定\alpha=0.01,则只有当观测到“女士答对8次”时才会拒绝原假设。
可见,如果我们希望犯第I类错误的概率越小(即 \alpha 越小),对证据的要求就越高( k 值越大)。
这里的 \alpha 即为显著性水平。图4、图5分别给出了显著性水平为0.05和0.04时的 k 值和拒绝域(红褐色部分)。
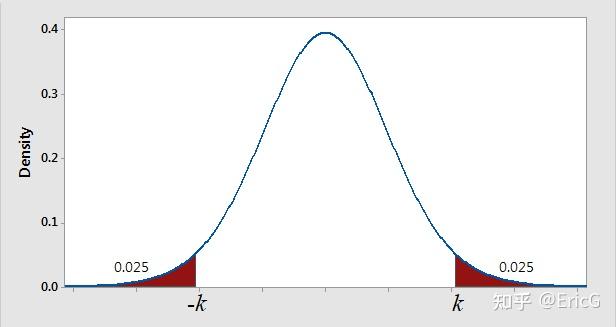
图4:显著性水平为0.05的 值和拒绝域(红褐色部分)
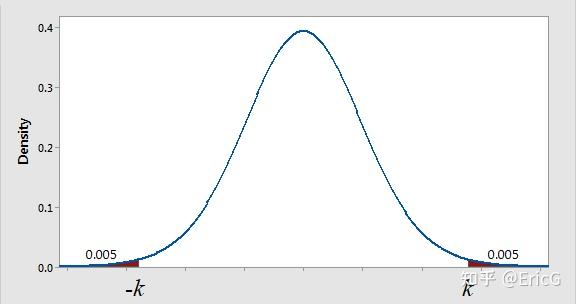
图5:显著性水平为0.01的 值和拒绝域(红褐色部分)
按照 \alpha 的定义:
P(H_0被拒绝|H_0为真) \le \alpha \;\;\;\; (2) \\
当为H_0真时,检验统计量 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} 服从标准正态分布;并且,由前文可知,“H_0被拒绝”这一事件等价于 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \ge k;于是,(2)式的左边等价于:
P(H_0被拒绝|H_0为真) = P\left\{ \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \ge k \right\} \;\;\;\; (3) \\
由于只允许犯第I类错误的概率最大为\alpha,令(2)式取等号,即当
P\left\{ \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \ge k \right\} = \alpha \;\;\;\; (4) \\
时,即可得到 k 的最小值。根据标准正态分布的分位点的定义可得(如图6):
k = z_{\alpha/2} \\
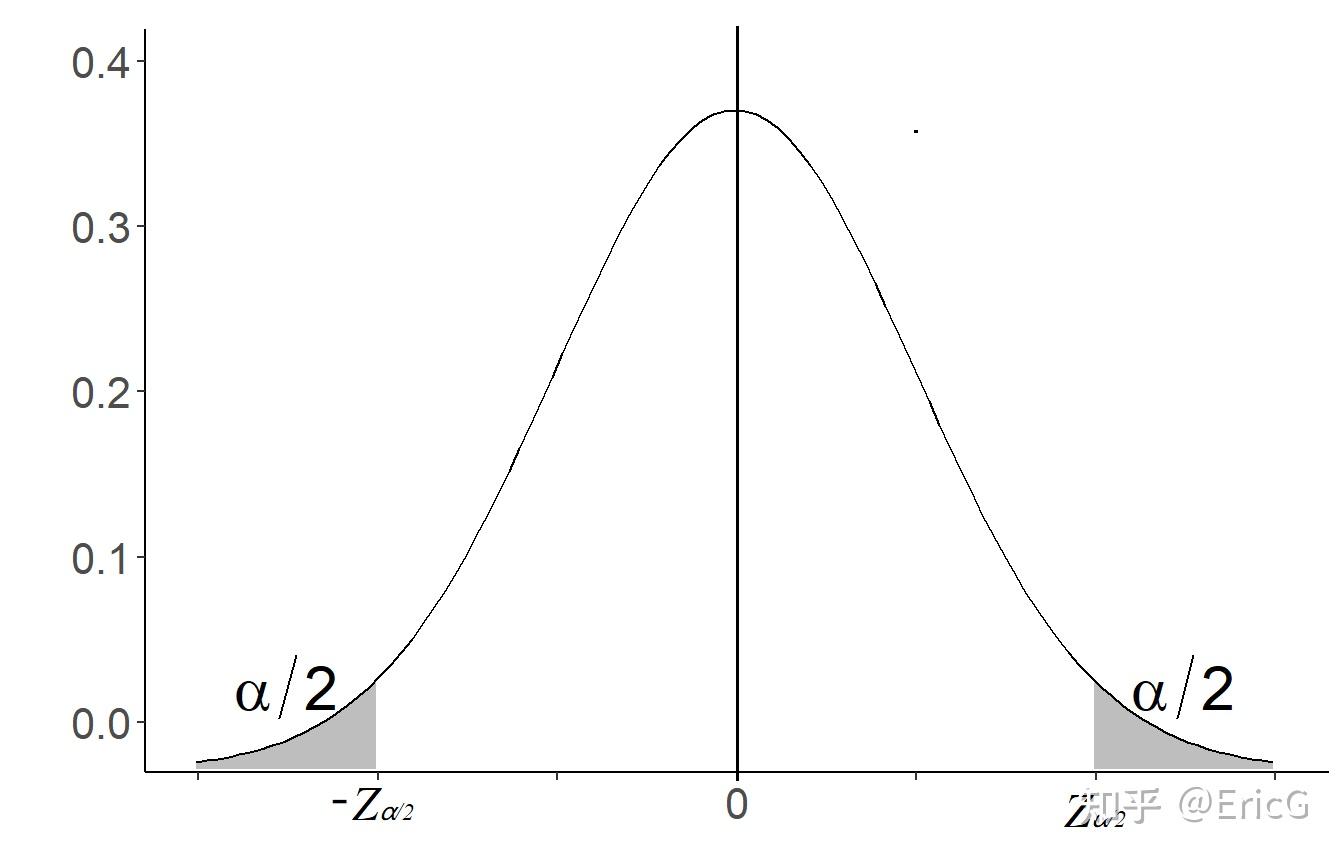
图6:标准正态分布的分位点
因此,若检验统计量满足 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} \ge z_{\alpha/2},则拒绝H_0。反之,若\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} < z_{\alpha/2},则接受H_0。
如选取\alpha=0.05,则 k=z_{\alpha/2}=z_{0.025}=1.96;如取\alpha=0.01,则 k=z_{\alpha/2}=z_{0.005}=2.576。需要说明的是,显著性水平的选择是主观的。
\frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}}又被称为Z统计量;以上这种利用 Z统计量进行检验的方法称为Z检验法。
如果总体标准差 \sigma 未知时,可以用样本方差 s 替代。此时,检验统计量 \frac{|\overline{x}-\mu_{0}|}{s/\sqrt{n}} 服从自由度为 n-1 的 t 分布。我们可以根据 t 分布临界值表确定出阈值 k 的大小。这种利用统计量 \frac{|\overline{x}-\mu_{0}|}{s/\sqrt{n}} 进行检验的方法称为t检验法。
其它的检验统计量(如卡方检验统计量)也可以用类似的方法从相应的分布表中确定出阈值。
图1:Logit模型参数估计结果示例(Biogeme)
讲到这里,您再回头看图1中的t-test那一列(即相应的t检验统计量的值),是不是已经找到感觉了...

p 值
给定显著性水平 \alpha,我们便可以确定拒绝域的范围,如图6所示。若检验统计量的值落入拒绝域,便可拒绝原假设。
p 值同样可以用于判断是否拒绝原假设。通俗的来说,p 值代表:在假设原假设(H_0)正确时,出现当前证据或更强的证据的概率。
重点在后半部分——更强的证据。
继续上面的第二个例子。我们观测到的样本均值 \bar{x}=(0.497+0.506+0.518+0.524+0.498+0.511+0.520+0.515+0.512)/9 = 0.511;相应的假设检验统计量的值 \frac{|\overline{x}-\mu_{0}|}{\sigma/\sqrt{n}} = \frac{|0.511-0.5|}{0.015/3} = 2.2。
本例中,当前证据指的是检验统计量的值= 2.2;更强的证据指的是检验统计量的值 \gt 2.2(检验统计量的值越大,说明 \overline{x} 与 \mu_{0} 的偏差越大)。合并起来,本例中的 p 值代表的就是检验统计量 \ge 2.2 的概率(图7中黑色部分的面积)。
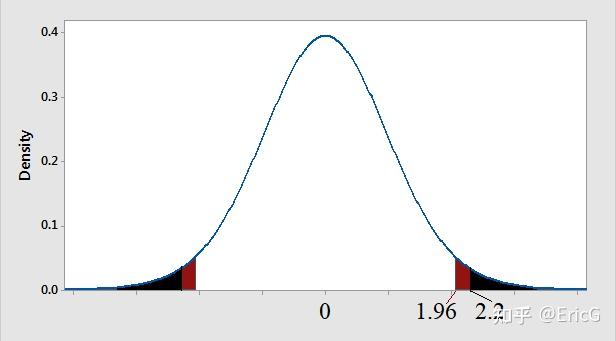
图7: 值等于检验统计量 ≥2.2 的概率(黑色部分的面积)
p 值是从样本中计算得到的;它反应了样本中提供的证据的强度。 p 值越小,说明样本提供的证据越强,对原假设越不利。将 p 值与事先规定的 \alpha 比较:若 p \le \alpha,则拒绝原假设;反之,则接受。
图1:Logit模型参数估计结果示例(Biogeme)
讲到这里,您再回头看图1中的p-value那一列,是不是已经很有感觉了:)

小结
小结一下假设检验的基本步骤:
- 提出原假设与备择假设
- 从所研究总体中出抽取一个随机样本
- 构造检验统计量
- 根据显著性水平确定拒绝域临界值
- 计算检验统计量与临界值进行比较
小练习
结束本文之前,留几个小练习供大家思考:
- (1)判断正误:如果假设检验的结果不能拒绝原假设,那就说明原假设是正确的。
- (2)判断正误:当我们拒绝原假设的时候,我们会犯第I类错误。
- (3)判断正误:如果原假设实际上假的但是我们没有拒绝它,此时我们犯了第II类错误。
- (4)判断正误:如果显著性水平α=0.01时我们拒绝了原假设,那么,当α设置为0.05时,我们依然会拒绝原假设。
答案请参见微信公众号文章:《假设检验——这一篇文章就够了(练习答案)》
【本篇完】
<hr/>DCM笔记的全部文章列表
入门篇
二项Logit/Probit理论篇:
多项Logit(MNL)理论与实战::
嵌套Logit(NL):
Biogeme:
其它:
如果您觉得本篇干货满满,请您动动手指,点赞、留言、分享三连,谢谢!
- END -
原文地址:https://zhuanlan.zhihu.com/p/436137583 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-13 16:42
发表于 2025-3-13 16:42



