金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
1 单正态总体
假设  是一个随机样本,服从正态分布 是一个随机样本,服从正态分布  。 。
考虑以下与参数  有关的假设检验。其中 有关的假设检验。其中  与显著性水平 与显著性水平  为预先设定且已知。 为预先设定且已知。
A)  ; ;
B)  ; ;
C)  ; ;
1.1 当  为已知参数 为已知参数
A) ;
已知,样本均值  是关于 的一个无偏点估计。并且,从直觉出发,我们容易认同在 是关于 的一个无偏点估计。并且,从直觉出发,我们容易认同在  很大时应该拒绝零假设 很大时应该拒绝零假设  。所以,我们可以把拒绝域写作如下形式: 。所以,我们可以把拒绝域写作如下形式:  。接下来的任务转变为求解临界值 。接下来的任务转变为求解临界值  。 。
假设零假设为真,对 进行变形,可知检验统计量  服从如下分布 服从如下分布

拒绝域的形式可改写为:  。接下来的任务转变为求解 。接下来的任务转变为求解  。 。
已知显著性水平为 ,根据显著性水平的定义 
从而可以确定  。拒绝域确定为: 。拒绝域确定为:  。 。
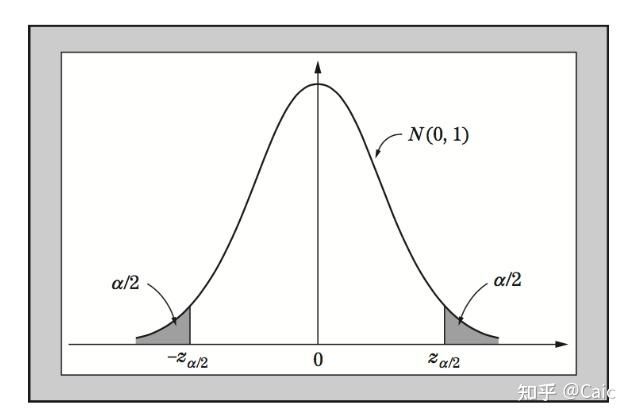
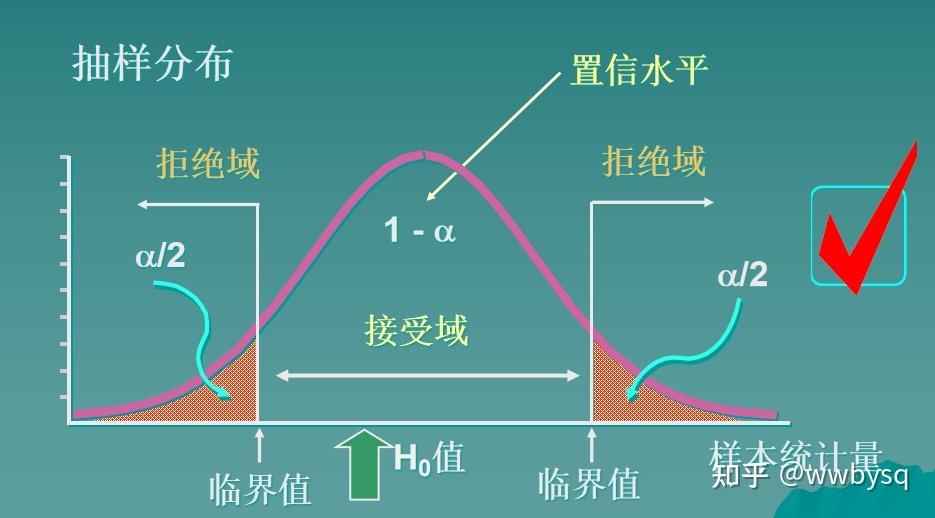
阴影区域为拒绝域(来自清华大学王江典老师课件)
进一步,得到功效函数  为 为

其中,  为标准正态分布的分布函数。 为标准正态分布的分布函数。
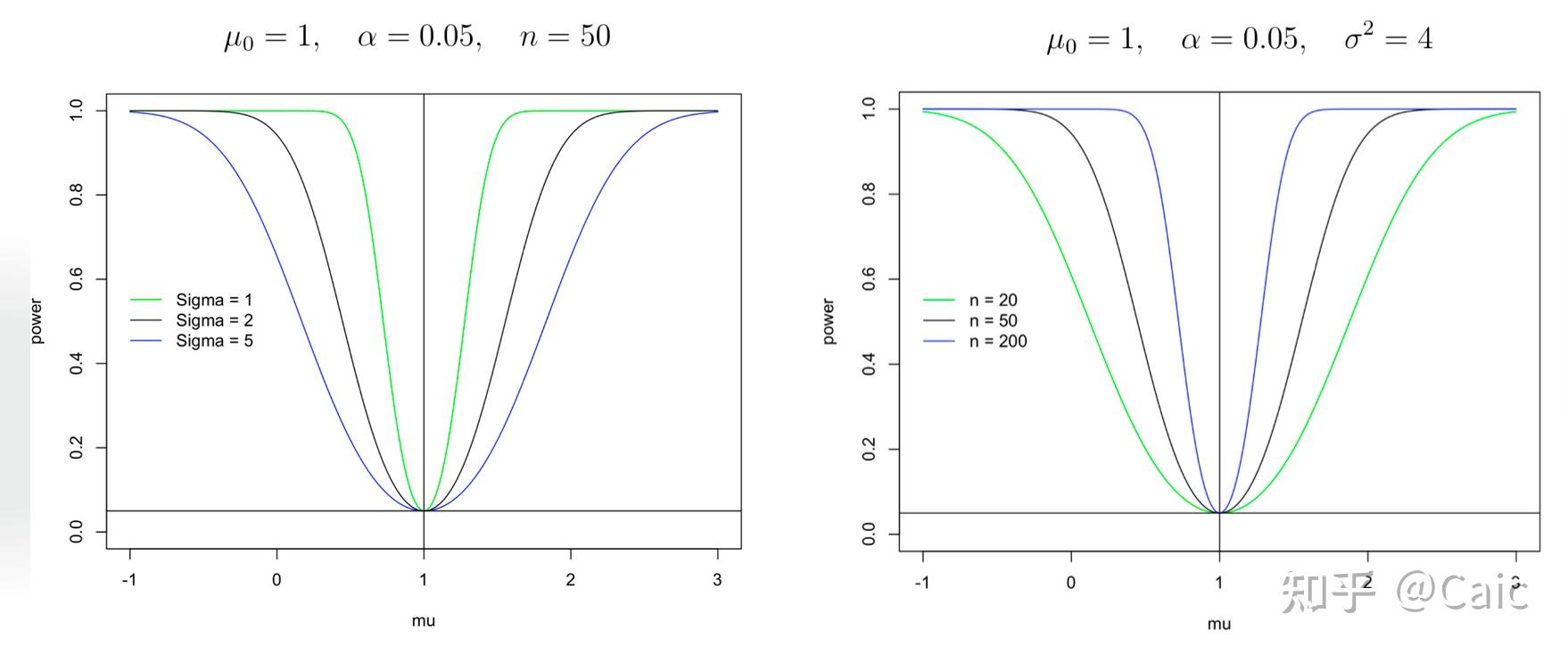
对功效函数的数值模拟(来自清华大学王江典老师课件)
发现该功效函数有两个特别的性质:1)  ;2) 当 ;2) 当  时, 时,  单调递增。 单调递增。 此外,还可以引入样本方差  ,构造另一种形式的拒绝域: ,构造另一种形式的拒绝域:  。选取另一种检验统计量 。选取另一种检验统计量  ,当零假设为真时,服从如下分布 ,当零假设为真时,服从如下分布

此时,拒绝域形如:  。又已知显著性水平为 ,根据定义 。又已知显著性水平为 ,根据定义
 从而可以确定 从而可以确定  。 拒绝域为: 。 拒绝域为:  。 。
此时的功效函数为

比起第一种来说,非常复杂,但这种功效函数可以适用于 未知的情形。
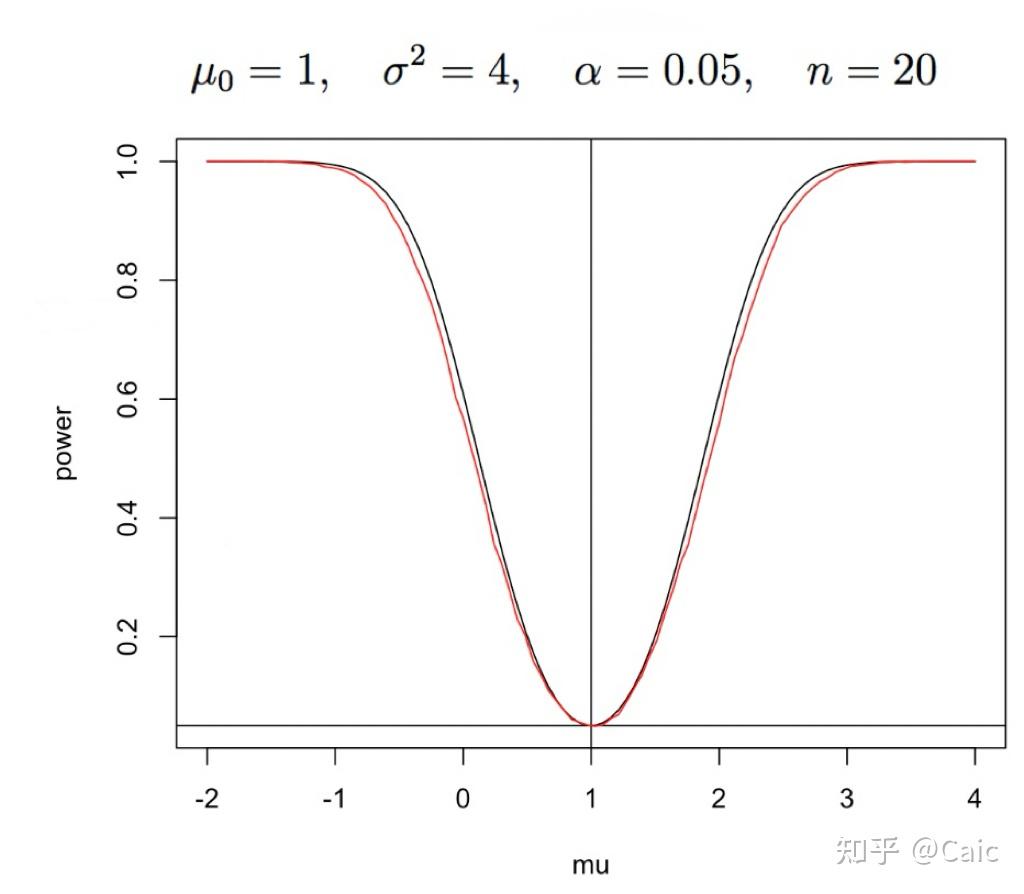
黑:一;红:二(来自清华大学王江典老师课件)
B) ;
构造检验统计量为  ,所以对应的拒绝域形如: ,所以对应的拒绝域形如:  。接下来的任务转变为求解 。已知显著性水平为 ,根据显著性水平的定义 。接下来的任务转变为求解 。已知显著性水平为 ,根据显著性水平的定义 
从而确定  。拒绝域为: 。拒绝域为:  。 。
进一步,得到功效函数为

是单调递增函数,说明了我们刚刚得到的拒绝域是恰当的。
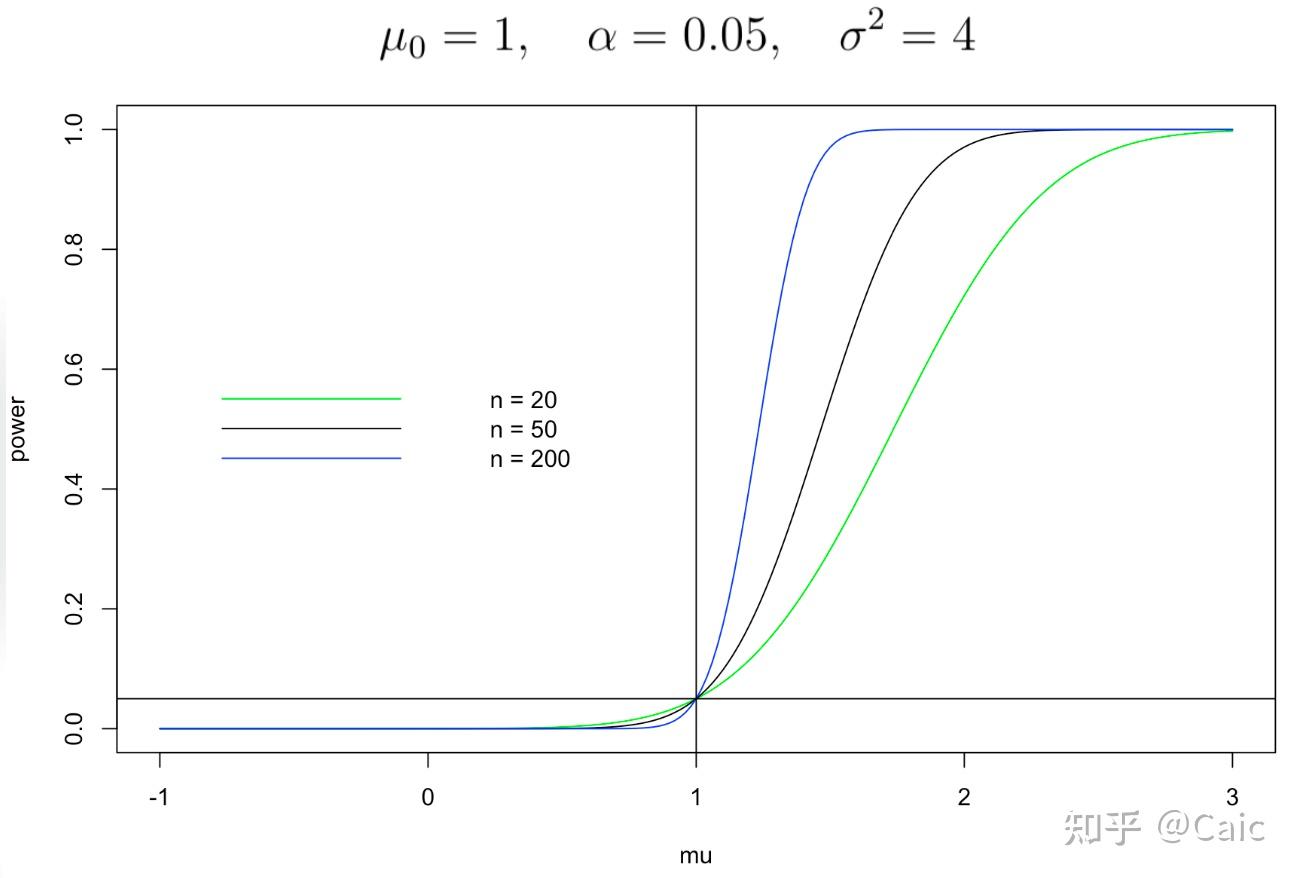
(来自清华大学王江典老师课件)
C) ;
此时也取检验统计量为 ,经过 B) 中类似的讨论,得到拒绝域 
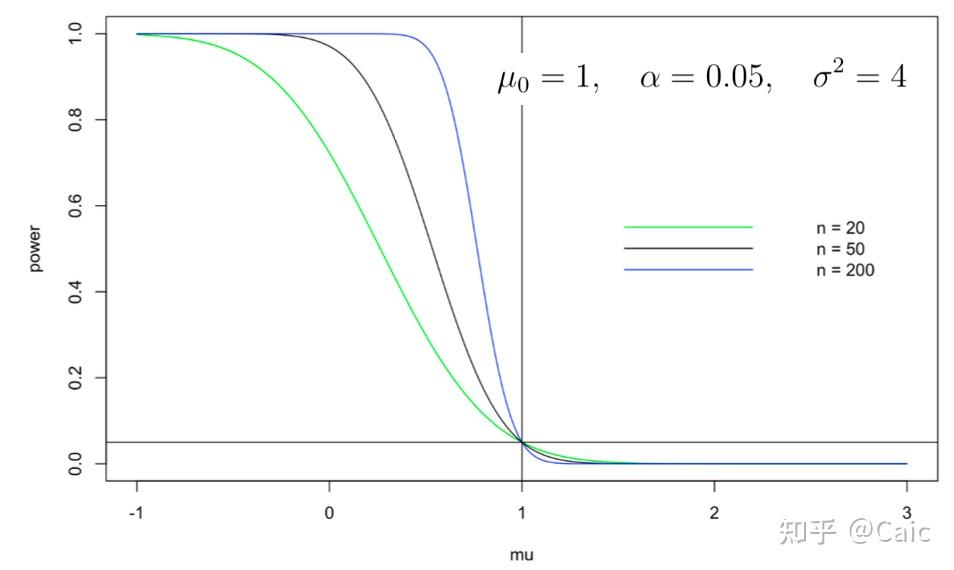
(来自清华大学王江典老师课件)
1.2 当 为未知参数
此时,采取 1.1 A) 中的处理,将检验统计量中的  都替换为样本标准差 都替换为样本标准差  ,为 ,为  。此时得到各个检验的拒绝域分别为 。此时得到各个检验的拒绝域分别为
A)  ; ;
B)  ; ;
C)  ; ;
以及各自的功效函数为

这种基于  统计的假设检验,被称为单样本 检验 / One Sample Test。 统计的假设检验,被称为单样本 检验 / One Sample Test。

(来自清华大学王江典老师课件)
考虑以下与参数 有关的假设检验。其中  与显著性水平 为预先设定且已知。 与显著性水平 为预先设定且已知。
D)  ; ;
E)  ; ;
F)  ; ;
1.3 当 为未知参数
选取检测统计量为 
拒绝域应当形如  , ,  , ,  。基于显著性水平的定义 。基于显著性水平的定义  可以求解得到待定系数的具体取值。从而,每个检验的拒绝域的具体形式如下 可以求解得到待定系数的具体取值。从而,每个检验的拒绝域的具体形式如下
D)  ; ;
E)  ; ;
F)  ; ;
1.4 当 为已知参数
设  ,选取检测统计量为 ,选取检测统计量为 
拒绝域应当形如 , , 。基于显著性水平的定义 可以求解得到待定系数的具体取值。从而,每个检验的拒绝域的具体形式如下
D)  ; ;
E)  ; ;
F)  ; ;
这种基于  统计的假设检验,被称为 检验 / Test。 统计的假设检验,被称为 检验 / Test。

(来自清华大学王江典老师课件)
<hr/>2 非正态总体
假设 是一个随机样本,服从二项分布  。其中参数 。其中参数  未知。 未知。
考虑以下与参数 有关的假设检验。其中  与显著性水平 为预先设定且已知。 与显著性水平 为预先设定且已知。
A)  ; ;
B)  ; ;
C)  ; ;
2.1
假设检验统计量为  。显然, 。显然,  是一个关于 的无偏点估计,因此在 是一个关于 的无偏点估计,因此在  或者 或者  很大时,我们直觉上会倾向于拒绝零假设,猜测拒绝域形如: 很大时,我们直觉上会倾向于拒绝零假设,猜测拒绝域形如: 。 。
已知,对于非随机检验,显著性水平 的定义为

但是对于随机检验来说,在离散的分布下,  的概率可能刚好小于 , 的概率可能刚好小于 ,  的概率又刚好大于 。从而不存在一个整数 能满足 的概率又刚好大于 。从而不存在一个整数 能满足  。 。
所以取随机检验函数  为 为 
我们可以这样理解随机检验函数:
当  ,判定为接受 ; ,判定为接受 ;
当 ,判定为拒绝 ;
当  ,对 ,对  进行调整,抛一枚硬币,正面的概率为 进行调整,抛一枚硬币,正面的概率为  ,抛到正面就判定为拒绝 。 ,抛到正面就判定为拒绝 。 得到功效函数  为 为

因为 ,在取定  后, 后,  与 与  的值是可计算的。因此,在确定了临界值 的一个具体取值后,根据上式我们可以确定 的值是可计算的。因此,在确定了临界值 的一个具体取值后,根据上式我们可以确定  的取值。 的取值。
例如,如果我们选取一个样本,  , ,  , ,  。在零假设下有 。在零假设下有 
如果选取  ,那么 ,那么  。于是随机检验函数为 。于是随机检验函数为 
2.2
同样地,我们选取检验统计量 ,并且拒绝域形如:  。同样有随机检验函数形如 。同样有随机检验函数形如

得到功效函数 
样本取定后,这些都是可计算的。
2.3
仍然选取检验统计量 ,拒绝域: 。 。
随机检验函数形如 
根据显著性水平 的定义

在样本取定后,这些都是可计算的。
<hr/>3 双正态总体
假设  是一个随机样本,服从正态分布 是一个随机样本,服从正态分布  ; ; 也是一个随机样本,服从正态分布 也是一个随机样本,服从正态分布  。 。
考虑以下与参数  有关的假设检验。其中 与显著性水平 为预先设定且已知。 有关的假设检验。其中 与显著性水平 为预先设定且已知。
A)  ; ;
B)  ; ;
C)  ; ;
3.1  和 和  均已知 均已知
先考虑双边检验 。显然,  是一个关于 的无偏点估计。并且,当 是一个关于 的无偏点估计。并且,当  很大时,我们会在直觉上倾向于拒绝零假设。并且此时拒绝域应当形如: 很大时,我们会在直觉上倾向于拒绝零假设。并且此时拒绝域应当形如:  。 。
具体地,我们将选取检验统计量为

此时的拒绝域为:  。 。
根据显著性水平的定义有

所以,可以确定 。另外两种检验都可以通过类似的方法确定拒绝域。总体结果如下:
A)  ; ;
B)  ; ;
C)  ; ;
3.2  但未知 但未知
这种情况被称为双样本 检验 / Two Sample Test。选取检验统计量 为 
同样地,按照显著性水平的定义,可以得到各个检验的拒绝域分别为
A)  ; ;
B)  ; ;
C)  ; ;

(来自清华大学王江典老师课件)
3.3  且未知 且未知
选取检验统计量  为 为 
在零假设成立时, 不服从 分布,只能采用渐进的方法,近似于  分布。其中,自由度 为 分布。其中,自由度 为

对上式四舍五入取最接近的整数。
现在,考虑以下与参数  有关的假设检验。其中显著性水平 为预先设定且已知。 有关的假设检验。其中显著性水平 为预先设定且已知。
D)  ; ;
E)  ; ;
F)  ; ;
3.4  和 和  未知 未知
选取检验统计量  为 为

拒绝域形如:  。 。
根据显著性水平的定义

所以,选取  和 和  。从而可以确定拒绝域的具体范围。同样地,另外两个假设检验也可以通过选取该检验统计量来求解拒绝域,总的结果如下: 。从而可以确定拒绝域的具体范围。同样地,另外两个假设检验也可以通过选取该检验统计量来求解拒绝域,总的结果如下:
D)  ; ;
E)  ; ;
F)  ; ;
3.5 和 已知
设  和 和  。此时,选取检验统计量 。此时,选取检验统计量  为 为

使用与 3.3 中一样的方法,得到各个假设检验的拒绝域如下:
D)  ; ;
E)  ; ;
F)  ; ;

(来自清华大学王江典老师课件)
3.6 示例
EX1:为研究正常成年男女血液红细胞平均数的差别,检验某地正常成年男子156人,女子74人,计算得到男女红细胞的平均数和样本标准差分别为:男,  万 万 , ,  万;男, 万;男,  万, 万,  万。假定正常男女红细胞数分别服从正态分布,且方差相同(但未知)。检验正常成年人红细胞数是否与性别有关(取显著水平 万。假定正常男女红细胞数分别服从正态分布,且方差相同(但未知)。检验正常成年人红细胞数是否与性别有关(取显著水平  )。 )。
转化为统计学语言,即考虑如下假设检验:  。 。
根据 3.2 中的讨论,易知此时的拒绝域为: 
直接带入题给数据,得到

拒绝零假设,即正常成年人红细胞数确实与性别有关,P 值为  。 。
EX2:为了考察一种安眠药的效果,记录了  个失眠患者服药前的每晚睡眠时间 个失眠患者服药前的每晚睡眠时间  和服用此安眠药后的每晚睡眠时间 和服用此安眠药后的每晚睡眠时间  。其中 。其中  是第 是第  个患者不服用安眠药和服用安眠药每晚的睡眠时间,请分析该安眠药的效果。 个患者不服用安眠药和服用安眠药每晚的睡眠时间,请分析该安眠药的效果。
此时,  和 和  是两个不独立的随机样本,不能直接套用之前的讨论。设 是两个不独立的随机样本,不能直接套用之前的讨论。设  ,于是将问题转化为如下假设检验: ,于是将问题转化为如下假设检验:  。采用 1.2 中讨论的结果,拒绝域为: 。采用 1.2 中讨论的结果,拒绝域为:

EX3:有两台测量材料中某种金属含量的光谱仪A和B,为鉴定它们的质量有无显著差异,对金属含量不同的 9 件材料样品进行测量,得到 9 对观测值为

(来自清华大学王江典老师课件)
根据试验结果,在 下,能否判断这两台光谱仪的质量有无显著差异?
此时,仍然认为 和 是两个不独立的随机样本,设 ,将问题转化为如下假设检验: 。拒绝域为:  。 。
带入数据:  。 。

接受零假设,即认为这两台光谱仪的质量没有显著差异,P 值为  。 。
EX4:有两批样本大小皆为 6 的电子器材,分别测量其电阻,得到两组数据:均值  和 和  ;样本标准差 ;样本标准差  和 和  。假设这两组电阻数据分别服从不同的正态分布,方差皆未知且两组样本独立。问:两批电子器材的电阻是否相同?取 。假设这两组电阻数据分别服从不同的正态分布,方差皆未知且两组样本独立。问:两批电子器材的电阻是否相同?取  。 。
尽管方差均未知,但可以先检验两组方差是否相同,选取假设检验:  。根据 3.4 中的讨论,拒绝域为: 。 。根据 3.4 中的讨论,拒绝域为: 。
带入题给数据  , ,  , ,  。 。

接受零假设,即认为两个样本的方差相同但未知。
此时,考虑电阻均值,选取假设检验:  。根据 3.2 中的讨论,拒绝域为 。根据 3.2 中的讨论,拒绝域为
带入题给数据:  。接受零假设,认为两批电子器材的电阻相同。 。接受零假设,认为两批电子器材的电阻相同。
<hr/>4 基于大样本定理的假设检验
假设 是一个随机样本,服从分布 :期望的分布均值为 ,分布方差为 ;样本均值为  ,样本方差为 ,样本方差为  。考虑以下两个统计量的分布。 。考虑以下两个统计量的分布。
1)  : :
如果  ,那么 ,那么  ; ;
如果  ,那么在 足够大时,根据 CLT 有 ,那么在 足够大时,根据 CLT 有  ; ;
2)  : :
如果 ,那么  ; ;
如果 ,那么在 足够大时,根据 CLT 和 Slutsky Thm 有  ; ;
4.1 当 和 未知时,对 进行假设检验
在 3.3 中我们曾简单讨论过,此时选取检验统计量 为
在零假设成立时, 不服从任何已知的分布,所以在 3.3 中我们采取了渐进分布来处理。
而当 足够大时,我们可以采取 CLT 和 Slutsky Thm 得到 在大样本下近似为  分布 分布

在零假设下,  。同样地,我们也可以得出大样本下的拒绝域为: 。同样地,我们也可以得出大样本下的拒绝域为:
A)  ; ;
B)  ; ;
C)  ; ;
EX:3.6 中的 EX1,但方差未必相同,检验正常成年人红细胞数是否与性别有关(取显著水平 )。
选取检验为: ,此时不再是 检验。

带入题给数据:  。 。

拒绝零假设,P 值为  。 。
4.2 对 的参数 进行假设检验
假设 是一个随机样本,服从伯努利分布 。给定显著性水平 。
根据 CLT 有

在零假设下 
从而得到各个假设检验下的拒绝域为
A)  ;; ;;
B)  ; ;
C)  ; ;
4.3 对  的参数 进行假设检验 的参数 进行假设检验
假设 是一个随机样本,服从柏松分布 。给定显著性水平 。
根据 CLT 有

在零假设下 
从而得到各个假设检验下的拒绝域为
A)  ;; ;;
B)  ; ;
C)  ; ;
4.4 自举法 / Bootstrapping Method
Bootstrapping Method 是一种统计学上的重采样技术,通过从原始样本中随机重复抽取,来构造伪样本,从而估计一个统计量的分布,并进一步评估估计值的变异性和置信区间。
无需依赖大样本量或正态分布的假设,在小样本研究或非参数研究中特别有用。

(来自清华大学王江典老师课件)
EX:1882年,西蒙·纽科姆做了一个测量光速的实验。下面的数字代表了光从波托马克河西岸的迈尔堡到达3721米外华盛顿纪念碑脚下的一面固定镜子所花费的测量时间。

(来自清华大学王江典老师课件)
在给出数据的单位中,目前公认的“真实”光速是33.02,请分析这些数据是否支持目前公认的光速。
运用 Bootstrapping Method 一般遵从以下流程:随机抽样若干个观察值,并进行替换,得到伪样本,计算 P 值。
本题采用的 R 语言代码如下,感兴趣的知友可以跑一下:
> speed <- c(28, -44, 29, 30, 26, 27, 22, 23, 33, 16, 24, 29, 24, 40, 21, 31, 34, -2, 25, 19)
> hist(speed)
> newspeed <- speed - mean(speed) + 33.02
> mean(newspeed)
> bstrap <~ cO
> for (i in 1:1000){
+ newsample <- sample(newspeed, 20, replace=T)
+ bstrap <- c(bstrap, mean(newsample))}
> hist(bstrap)
> (sum(bstrap < 21.75) + sum(bstrap > 44.29))/1000更多关于 Bootstrapping Method 的例子,可以参考以下知乎回答:
商胜彭:Bootstrapping算法(附python代码)什么是Bootstrapping? |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-5-11 12:24
发表于 2025-5-11 12:24