金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
Why PD and Dynamo ?
大模型推理服务长期面临三重矛盾:首 Token 生成速度(TTFT)、单 Token 生成时延(TPOT) 与资源利用率。传统架构将 Prefill(输入处理)与 Decoding(自回归生成)耦合在同一 GPU 上,导致两种负载互相掣肘:
- 算力错配:Prefill 阶段需并行计算长序列,而 Decoding 阶段依赖高频次显存读写逐 Token 生成,前者吃满算力时后者被迫排队;
- 资源浪费:Decoding 阶段 GPU 利用率常不足 30%,但 Prefill 突发流量可能挤占生成带宽,造成「饥饿式延迟」;
- 弹性缺失:长短文本混合场景下,单卡难以动态分配 Prefill 与 Decoding 资源,被迫超配硬件。
PD 分离架构通过解耦计算图与异构资源池化打破僵局:将 Prefill 阶段卸载到高算力设备,Decoding 交由大显存/高带宽集群,通过分布式 KV Cache 调度实现「术业专攻」。以 DistServe 论文为例,分离后单卡吞吐提升 2-4.5 倍,而月之暗面 Kimi 的 Mooncake 系统更通过全局 KV Cache 池化实现长文本推理成本下降 30%(上述数据大家自行甄别)。
关于更多的 PD 分离相关知识可以参考以下大佬的文章:
Mooncake阅读笔记:深入学习以Cache为中心的调度思想,谱写LLM服务降本增效新篇章 - 方佳瑞的文章 - 知乎 https://zhuanlan.zhihu.com/p/706097807
大模型推理分离架构五虎上将 - 手抓饼熊的文章 - 知乎 https://zhuanlan.zhihu.com/p/706218732
Mooncake (1): 在月之暗面做月饼,Kimi 以 KVCache 为中心的分离式推理架构 - ZHANG Mingxing的文章 - 知乎 https://zhuanlan.zhihu.com/p/705754254

PD 分离会盟
从学术界的 Splitwise、DistServe 到工业界的 Mooncake,PD 分离已成为头部厂商的「降本利器」。NVIDIA 推出的 Dynamo 框架进一步将这一理念工程化。为什么要选择介绍 Dynamo 呢?抛开其他原因,我觉得在框架之上搭一层 router 的这种形式,与我的想法不谋而合(不要脸)。早在思考speculative sampling和prompt compression的时候,就觉得可以抽离出一个专门的 router 来做这些事情,包括但不限于:判断 prompt 难易程度,tokenize流程, 处理 cache 的问题,判断直接使用 draft model or full model,负载均衡或者是调度。并且 @Byron Hsu 也于去年 11 月在SGLANG slack上 create 了 dev-router 的channel 。所以借Dynamo 发布的东风,鄙人也可以学习一下 router 的设计以及架构。
其实官方的 repo 已经提供了很多文档来细致介绍整体的架构设计以及实现细节,但是缺少从coding角度的说明。再加上核心代码是用 Rust 编写,存在一定的理解成本。因此本文会从代码流程的角度出发,将 Dynamo 拆解为三个部分来介绍一下 Dynamo 的具体实现,以及其中一些巧思。有不足或者理解错误之处,望各位大佬多多指出讨论。
正文
话不多说,我们从这张图开始。这是根据 Dynamo Repo 中的原始架构图修改而成的,标注出了 components 的一些核心功能以及要介绍的核心 funcation,可以配合之后的解释来更好的理解。
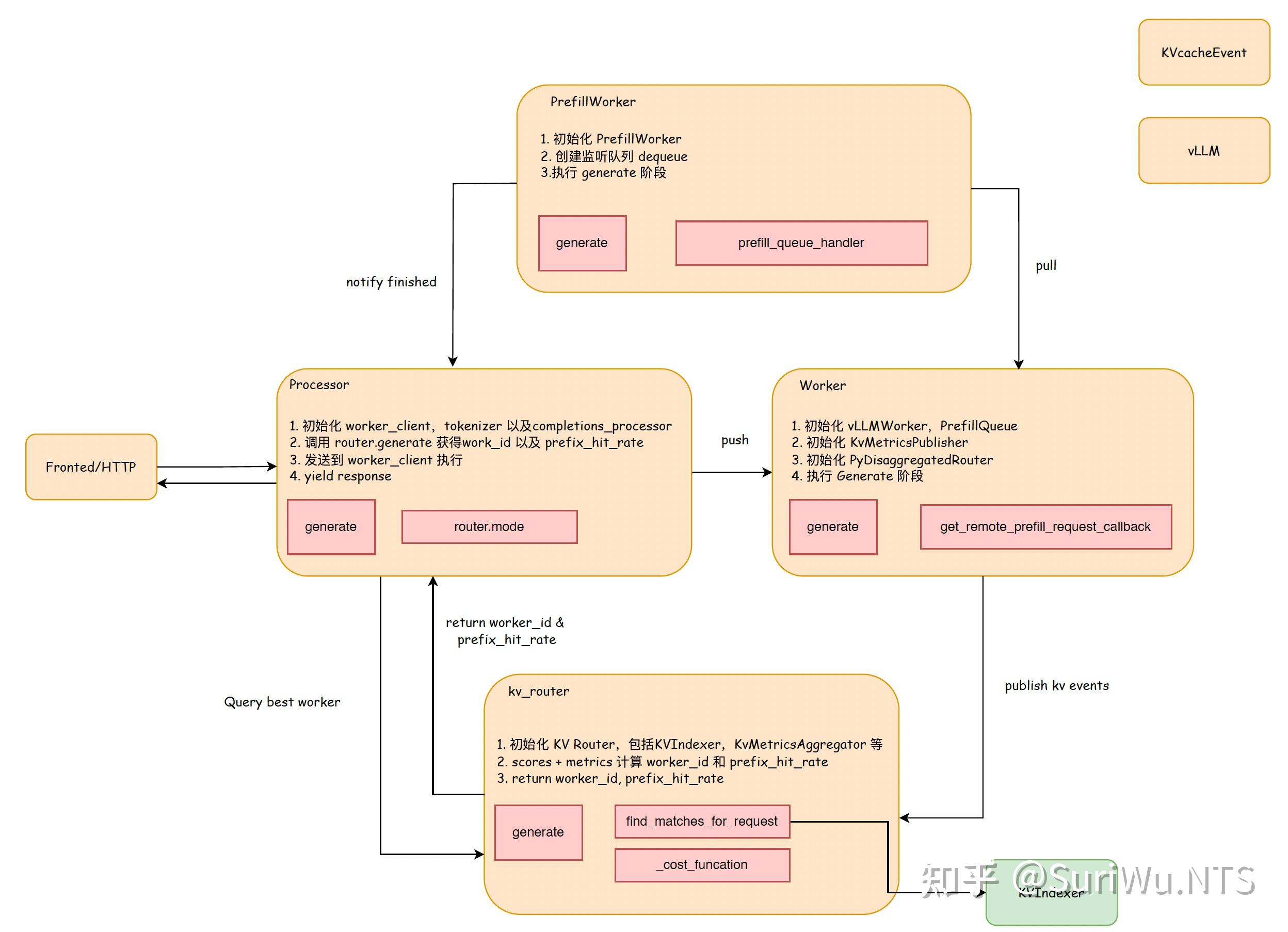
Fig1. 核心 components 结构图
Fronted
负责add 或者 remove model,启动 http 服务,这个不是太重要。大家可以自行看一下代码。
Processor
Processor 的核心逻辑比较简单,负责前后处理的流程。除开上图提到的初始化部分,其核心功能就是根据 router_mode(后续默认按照 “kv”模式)以及输入 tokens来确定 Worker 的选择方式。然后将请求调用到对应的 worker_client 执行推理操作。最后会接收返回数据并 yield。 由于其核心执行代码都是在其他 components中,因此我们只需要大致了解 Processor 的作用即可。 Processor 大致的 workflow 如下:
用户请求 → Processor接收raw_request → parse_raw_request进行tokenization → 选择合适的vLLMWorker(基于路由策略)→ 发请求到Worker → Worker执行模型推理 → 返回生成结果 → Processor处理和格式化响应 → 流式返回给用户
Worker
Worker 负责推理阶段,决策是否做 remote prefill,以及维护与inference engine的 connection。 初始化 worker,包括 engine, nats server,PrefillQueue以及 KvMetricsPublisher 等。这里着重聊一下 PrefillQueue 和 KvMetricsPublisher。
PrefillQueue(NATSQueue)是一个异步消息队列,可以灵活实现 push 或者 fetch。如果确定 request 需要在 remote 执行,会通过enqueue_task入队,然后在对应的 prefillworker 上执行dequeue_task出队,进行下一步流程。
KvMetricsPublisher是一个基于 KvMetrics 的 Publisher。Publish 是Dynamo 中的一个常见概念,会发布 Event 到指定的 subject,这样所有订阅了该 subject 的都会收到该 Event (后续会详细介绍 KvCacheEvent 的一系列逻辑)。其中 KVmetrics 包括的参数如下,但是最后能够用来判断 Worker 负载的只有KvMetricsAggregator里的指标:num_requests_waiting, gpu_cache_usgae以及gpu_prefix_cache_hit_rate。
if self.engine_args.router == "kv":
assert self.engine_client is not None, "engine_client was not initialized"
self.engine_client.set_metrics_publisher(self.metrics_publisher)
# Initially send dummy metrics to kick start,
# vLLM will not update stat until forward pass is triggered
self.metrics_publisher.publish(
0, # request_active_slots
1024, # request_total_slots
0, # kv_active_blocks
1024, # kv_total_blocks
0, # num_requests_waiting
0.0, # gpu_cache_usage_perc
0.0, # gpu_prefix_cache_hit_rate
)
task = asyncio.create_task(self.create_metrics_publisher_endpoint())
task.add_done_callback(
lambda _: print("metrics publisher endpoint created")
)
然后是 generate 函数:在disaggregated_router的情况下(反之则always remote prefill),根据promts 的长度,prefix_hit_rate,以及 prefill_queue_size 来判断是否在远端做 prefill。这个算是worker 里面的核心判断逻辑,其代码如下:
def prefill_remote(
self, prompt_length: int, prefix_hit_rate: float, queue_size: int
):
absolute_prefill_length = int(prompt_length * (1 - prefix_hit_rate))
# TODO: consider size of each request in the queue when making the decision
decision = (
absolute_prefill_length > self.max_local_prefill_length
and queue_size < self.max_prefill_queue_size
)
vllm_logger.info(
f"Remote prefill: {decision} (prefill length: {absolute_prefill_length}/{prompt_length}, prefill queue size: {queue_size}/{self.max_prefill_queue_size})"
)
return decision一句话总结就是:打开 remote prefill ,在prefill_queue 队列长度小于启动 yaml 设置的 max_prefill_queue_size 的情况下,绝对 prefill 长度(剔除 prefix hit rate 的占比)大于 yaml 设置的 max_local_prefill_length的时候,启用 remote prefill。 具体执行方式是将下列 callback 函数传递给RemotePrefillParams,然后交由对应的 engine 来处理。
def get_remote_prefill_request_callback(self):
# TODO: integrate prefill_queue to dynamo endpoint
async def callback(request: RemotePrefillRequest):
async with PrefillQueue.get_instance(
nats_server=self._prefill_queue_nats_server,
stream_name=self._prefill_queue_stream_name,
) as prefill_queue:
await prefill_queue.enqueue_prefill_request(request)
return callbackKV router
KV router 主要功能是根据 workers 的各项指标来获得分数,从而来选择使用哪一个 worker。由于这个地方会涉及到 Rust 里面的匹配计算逻辑,所以我会先梳理一下 KV router 的功能,然后再进入到 Rust 里面来着重介绍。 首先是初始化 router和 KV 组件,包括KVIndexer,KvMetricsAggregator 等。 这里的 KV 组件都是为了后面计算 Router 的负载和分数服务。
kv_listener = self.runtime.namespace("dynamo").component("VllmWorker")
await kv_listener.create_service()
self.indexer = KvIndexer(kv_listener, self.args.block_size)
self.metrics_aggregator = KvMetricsAggregator(kv_listener)
print("KV Router initialized")然后是对应的 generate 函数:通过find_matches_for_request计算出的 scores + metrics + token_length 来计算出最佳的 worker_id 以及对应 prefix_hit_rate。
find_matches_for_request的具体实现很重要,我们先放在这里,走完后续_cost_funcation的流程之后回头再来看。
from dynamo.llm import AggregatedMetrics, KvIndexer, KvMetricsAggregator, OverlapScores
@dynamo_endpoint()
async def generate(self, request: Tokens) -> AsyncIterator[WorkerId]:
lora_id = 0
try:
scores = await self.indexer.find_matches_for_request(
request.tokens, lora_id
)
except Exception as e:
scores = {}
vllm_logger.exception(f"Error finding matches: {e}")
metrics = await self.metrics_aggregator.get_metrics()
worker_id, prefix_hit_rate = self._cost_function(
scores, metrics, len(request.tokens)
)
vllm_logger.info(
f"Scheduling to worker_id: {worker_id} with estimated prefix hit rate: {prefix_hit_rate}"
)
yield f"{worker_id}_{prefix_hit_rate}"cost_function 的核心计算逻辑如下:
其中 score 是匹配的 block 数量,worker_scores 是匹配的 tokens 数目/总的 token 长度。gpu_cache_usage 是metrics_aggregator中提取到的信息。normalized_waiting 是根据所有 workers 的 max waiting 进行的 normalized。最后再从worker_logits 里面拿到最大 logtis 对应的 worker_id (如果不止一个,则从中随机选取),并返回对应的worker_scores,作为prefix_hit_rate。
worker_scores[worker_id] = (
score * self.indexer.block_size() / token_length
)
worker_logits[worker_id] = 2 * worker_scores - gpu_cache_usage - normalized_waiting
vllm_logger.info(
f"Formula for {worker_id}: {worker_logits[worker_id]:.3f} = 2.0 * {score:.3f} - {gpu_cache_usage:.3f} - {normalized_waiting:.3f}"
)
其实到上述为止,整个 python 接口的核心功能都已经介绍完了。这些逻辑和实现都是比较直观简单的,大家可以先结合上面的Fig.1 来梳理清楚整个结构,对于 Dynamo 的功能和逻辑有一个粗浅的认识。
<hr/>接下来我们以kv_router 中 find_matches_for_request 这个函数为 Rust 的切入点,介绍一下其背后的执行逻辑。
KvIndexer
KvIndexer 的代码逻辑在dynamo/lib/llm/src/kv_router/indexer.rs,主要负责管理KV储存,处理 events 以及match requests。在 kv_router 中调用的find_matches_for_request会根据 tokens 和 kv_block_size 来计算 sequences 的 hash 值,然后进行实际的匹配流程。 首先 tokens 会根据 kv_block_size 来进行分块(不够 kv_block_size 的元素会被 remove 掉),然后以小字节序字节顺序将浮点数的内存表示形式返回为字节数组(https://rustwiki.org/zh-CN/std/primitive.f32.html#method.to_le_bytes),并展平成一维数组。接着再计算 Hash 值(具体计算方式参考https://docs.rs/xxhash-rust/latest/xxhash_rust/xxh3/fn.xxh3_64_with_seed.html)
async fn find_matches_for_request(
&self,
tokens: &[u32],
) -> Result<OverlapScores, KvRouterError> {
log::debug!(
"Finding matches for request tokens: {:?} / len: {}",
tokens,
tokens.len()
);
let sequence = compute_block_hash_for_seq(tokens, self.kv_block_size);
log::debug!("Computed sequence: {:?}", sequence);
self.find_matches(sequence).await
}
pub fn compute_block_hash_for_seq(tokens: &[u32], kv_block_size: usize) -> Vec<LocalBlockHash> {
tokens
.chunks_exact(kv_block_size) // Split into chunks of kv_block_size elements
.map(|chunk| {
let bytes: Vec<u8> = chunk
.iter()
.flat_map(|&num| num.to_le_bytes()) // Convert each i32 to its little-endian bytes
.collect();
compute_block_hash(&Bytes::from(bytes)) // Convert the byte Vec to Bytes
})
.collect()
}
完成 hash 值的计算之后,会执行 find_matches 的逻辑。首先会创建一个一次性的异步通信通道,然后将 sequence(计算出的 hash 值),early_exit(是否提前退出),resp(发送通道) 打包成一个 req(MachRequest)。然后会将 req通过 match_tx 通道发送出去,然后异步等待 resp_rx 通道接收返回结果。注意上面提到发送接收通道 resp_tx 和 resp_rx,match_tx和 match_rx 都是一一对应的。这意味着存在一个后台监控器会接收任务,实际处理之后再 resend 给 find_matches。
async fn find_matches(
&self,
sequence: Vec<LocalBlockHash>,
) -> Result<OverlapScores, KvRouterError> {
let (resp_tx, resp_rx) = oneshot::channel();
let req = MatchRequest {
sequence,
early_exit: false,
resp: resp_tx,
};
if let Err(e) = self.match_tx.send(req).await {
log::error!(
"Failed to send match request: {:?}; the indexer maybe offline",
e
);
return Err(KvRouterError::IndexerOffline);
}
resp_rx
.await
.map_err(|_| KvRouterError::IndexerDroppedRequest)
}
KvIndexer 会创建一个单线程来依次处理 remove worker,find_matches,处理cancelled 请求以及 apply event 时间。核心的匹配代码在RadixTree下的 find_matches 中。借用一下 Dynamo 中的描述:
The `RadixTree` struct represents the main data structure, with nodes (`RadixBlock`) containing children and associated worker IDs. RadixTree 的结构包括 root(根节点),lookup(查找表,包括两层 Hash表),expiration_duration(过期时间)。接下来我们进入它核心的 find_matches 逻辑:
整体流程会遍历 sequence 中的哈希块,并引用其下一个子节点的哈希块并进行匹配。如果子节点存在,那么会检测所有缓存该哈希块的workers_id,并更新 scores 值。接下来还会用rencent_uses(双向队列)检查一下 block 的访问时间,过期了的时间戳会被 pop_front 掉,新的access time 会被 push_back。同时也会把访问的频率记录下来(但目前还没有利用频率来判断)。最后如果启动了 early_exit(默认为 false),找到唯一匹配的worker就直接退出。
pub fn find_matches(&self, sequence: Vec<LocalBlockHash>, early_exit: bool) -> OverlapScores {
let mut scores = OverlapScores::new();
let mut current = self.root.clone();
let now = Instant::now();
for block_hash in sequence {
let next_block = {
let current_borrow = current.borrow();
current_borrow.children.get(&block_hash).cloned()
};
if let Some(block) = next_block {
scores.update_scores(&block.borrow().workers);
if let Some(expiration_duration) = self.expiration_duration {
let mut block_mut = block.borrow_mut();
while let Some(access_time) = block_mut.recent_uses.front() {
if now.duration_since(*access_time) > expiration_duration {
block_mut.recent_uses.pop_front();
} else {
break;
}
}
scores.add_frequency(block_mut.recent_uses.len());
block_mut.recent_uses.push_back(now);
}
if early_exit && block.borrow().workers.len() == 1 {
break;
}
current = block;
} else {
break;
}
}
scores
}
上面的例子可能比较抽象,我这边举一个简单的例子来帮助大家理解:
`假设现在存在序列[“我爱北京城门”],并且kv_block_size=2,假如经过上述的 tokenized,分块,字节转化,哈希化之后成为序列:[[432, 265],[251,234],[673,654]]。然后进行匹配:`
`第一个块[432, 265],发现 workers = {1, 2, 3} ,意味着 worker 1,2,3 都缓存了这个块,scores 更新之后会变成 scores = { 1:1, 2:1, 3:1 }`
`第二个块[251,234],发现 workers = {1, 2},意味着只有 worker 1,2 缓存了这个块,scores 更新之后会变成 scores = { 1:2, 2:2, 3:1 }
第三个块[673,654],发现 workers = {1},意味着只有 worker 1 缓存了这个块,scores 更新之后会变成 scores = { 1:3, 2:2, 3:1 }`
匹配统计完成之后,上述的 scores 就会被返回,进行 _cost_function 的计算。 上述例子的 scores 就是kv_router 代码中的返回值 scores,后续会被用来计算 cost_funcation 以及负载,从而来确定具体使用哪个 Worker。
try:
scores = await self.indexer.find_matches_for_request(
request.tokens, lora_id
)小结
本文以 python 接口为切入点,力图简洁的给大家介绍了 Dynamo 的组件功能,以及一些核心的逻辑。为了把整个功能的流程串起来,也附带介绍了一些简单的 Rust 代码。除了上述的组件以外,Nvidia 还提出了“Planner”,可以用来动态扩缩Prefill/Decode Worker,或者是实现两者的 role-switching。但是目前在 public repo 还没有实现,后续如果实现了(亦或是有其他关键更新),我也会在本文章中更新。希望大家多多关注!
后记
有些朋友可能会有疑问,KvIndexer 是怎么知道哪些 worker 缓存了哪些哈希块的信息?Fig.1 图中右上角的 vLLM 和 KvCacheEvent 部分具体承担了什么任务?Kv 的管理,传输以及通信是怎么处理的? 由于篇幅的原因,我会在后续的系列中给大家详细介绍。希望大家多多点赞收藏。
Dynamo 是一个设计很优秀的 PD 分离架构,虽然有一些复杂,但是也不失为一个好的学习样例,本文如果有任何错误或者遗漏之处,大家可以在评论区和谐讨论!
原文地址:https://zhuanlan.zhihu.com/p/1892956782365742153 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-4-13 06:07
发表于 2025-4-13 06:07
 提升卡
提升卡


