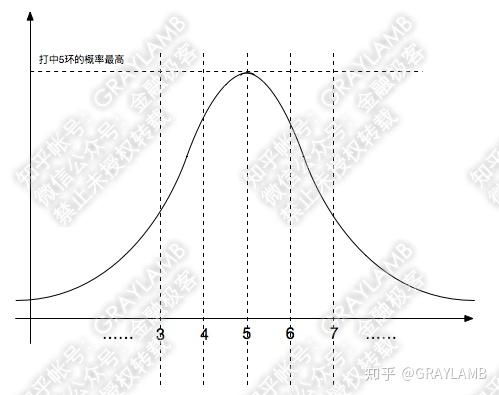
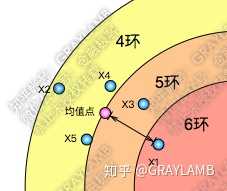
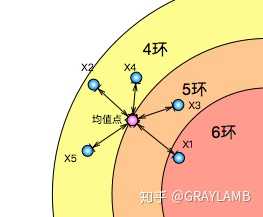
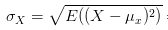金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
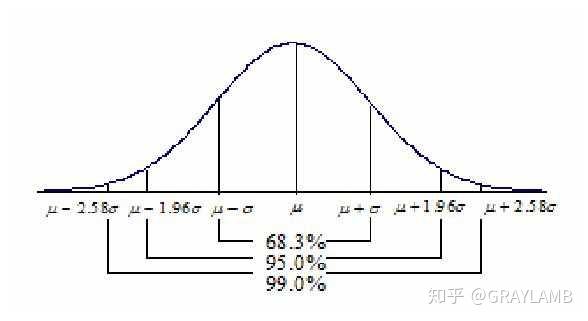
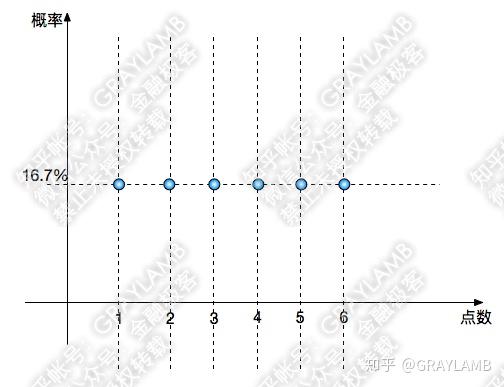
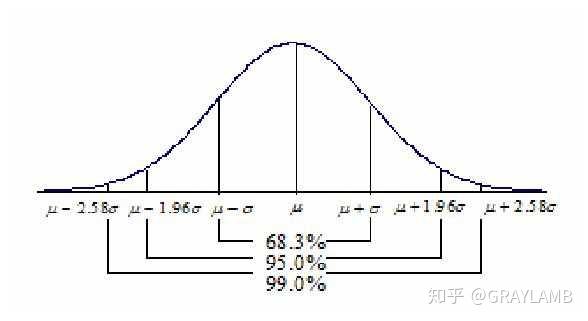
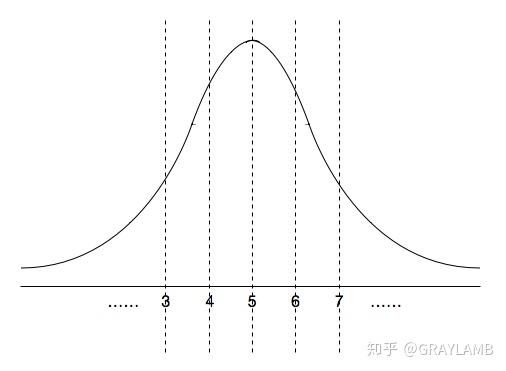
Lady tasting teaIn a famous example of hypothesis testing, known as the Lady tasting tea example, a female colleague of Fisher claimed to be able to tell whether the tea or the milk was added first to a cup. Fisher proposed to give her eight cups, four of each variety, in random order. One could then ask what the probability was for her getting the number she got correct, but just by chance. The null hypothesis was that the Lady had no such ability. The test statistic was a simple count of the number of successes in selecting the 4 cups. The critical region was the single case of 4 successes of 4 possible based on a conventional probability criterion (< 5%; 1 of 70 ≈ 1.4%). Fisher asserted that no alternative hypothesis was (ever) required. The lady correctly identified every cup which would be considered a statistically significant result.
copy自wiki:
http://en.wikipedia.org/wiki/Statistical_hypothesis_testing#Example
可能没有很好的回答lz的问题,不过可以和其他的回答参照一下。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-14 10:38
发表于 2025-3-14 10:38