金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
刚刚看了一下,作为菜狗-.-我更关心有啥能拿过来的东西不,顺便简单记录了一下 tricks(比较潦草,将就点哈),方便其他人去原文找对应章节学习。
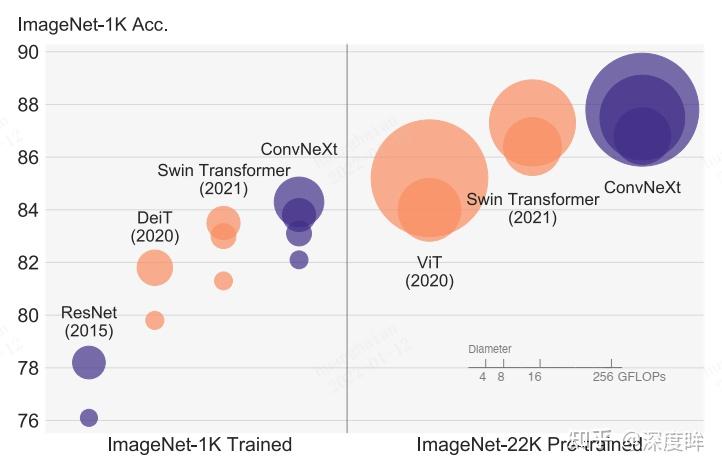
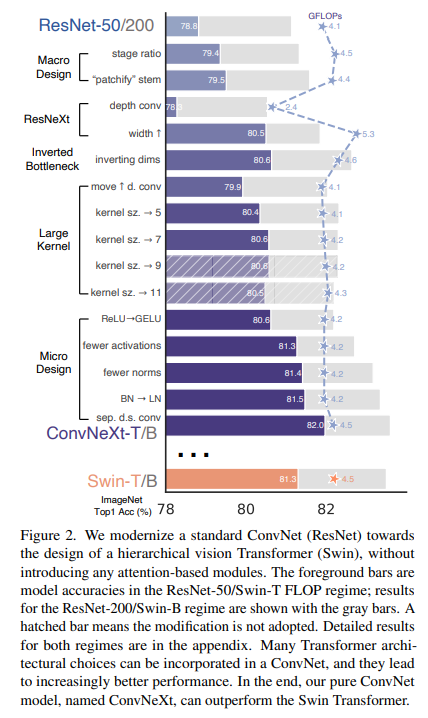
<hr/>概述:以ResNet50和Swim-T为例,作者把 ResNet50从 76.1 调/修改 到了 82.0(imageNet-1K),超过了Swin-T的81.3。
A ConvNet for the 2020s
- 文章干了这样一件事:逐步把 ResNet 改造(modernize)成 Transformer;
- Conv 具有内置偏置:平移不变性
- 滑动窗口的特点使得它本身效率就高;
- ViT丢弃了 Conv 的偏置,仅利用注意力机制就获得了很大的提升(不过这些前提是有大规模预训练,另外全局注意力的计算复杂度也比较大)
- 层级的 Transformer 使用混合设计克服了这个gap,例如 Swin-transformer;这表明 卷积从未落寞(原文:the essence of convolution is not becoming irrelevant; rather, it remains much desired and has never faded.)
- 高效训练ResNet50:A recent paper [76] demonstrates how a set of modern training techniques can significantly enhance the performance of a simple ResNet-50 model.
- 提升 ResNet 可能的 tips: The complete set of hyper-parameters we use can be found in Appendix A.1,在imageNet-1k上把 ResNet50 从 76.1 提到 78.8;
- 正文: ResNet 进行网络结构的逐步改造
Macro Design(大改动)
- 作者分析 swin-T 的设计,考虑了两点
- the stage compute ratio,
- 改变layer0~layer4的block数比值:(3,4,6,3)-> (3,3,9,3),这一点在 [50, 51] 中有人分析过;
- and the “stem cell” structure
- Changing stem to “Patchify”
- ResNet 中原先的 Stem cell(即kernel降维过程)为7x7 Conv + Stride=2 +max_pool,这样一次降维为 4倍;
- 作者仿照 Swin-T,用4x4, stride=4的卷积(即patchify,因为没有相交)
- 79.4->79.5
ResNeXt-ify(ResNeXt化)
- 用 depthwise conv 代替 bottleneck中的 3x3卷积(depthwise conv 只在每一 channel 上进行 spatial 信息交互,有点类似于 self-attention);
- 把网络的宽度从64 提到 96;
- 79.5->80.5
Inverted Bottleneck
- 在bottle neck上把维度变化的顺序进行了修改,原先是 大维度(channel维度)->小维度(此时进行d3x3空间大小降维)->大维度,从而减少计算量;
- 现在是 小维度->大维度(d3x3)->小维度,虽然本模块的计算量增加了,但输入输出的维度降低了,其他参与的模块的整体维度就小了,整个网络计算量也就小了;
- 80.5->80.6
Large Kernel Sizes
- Swin-T用的 Kernel 是 7x7,这在之前一些 ConvNet上也用过,不过过去的“黄金配置”是叠加 3x3 Conv,这样在 GPU 实现时硬件加速也很好;因此作者重新回顾了 大 kernel-sized 卷积的使用;
- 直接用 7x7 会导致参数里变大,作者把 Inverted Bottleneck 的空间降维 d3x3进行了移动(此时的与 swin-T的位置类似),从而在小维度上进行空间降维,节省了计算量;但也掉点了(作者称为暂时的掉点)
- 然后使用 7x7,此时点数又上升了,与之前结果相近,这说明 7x7 在相同参数量下效果一样;
- 点数没变,但为了与 Swin-T对齐会使用
Micro Design(小改动)
- 之前都是大改动,现在是小改动;
- 把 ReLU 换成 GELU;(精度没变,但是 transformer中都用了,作者为了统一也用了)
- 把 激活层减少(具体结构见论文)
- 把多余的 BN 去掉,只在 1x1 前留一个
- 用LN代替剩下的那个BN
- 单独的下采样层
- ResNet的下采样通常是 3x3,s=2(如果有residual就有一个1x1,s=2);
- 与 swin-T 对齐,改为 2x2, s=2,此时生成的特征的感受野是独立的(无交叠)
- 由于改了后网络训练不稳定,多加了几个Norm层,分别在 下采样前,stem后和 GAP后
- 81.5->82.0
综上,作者阐述并未用新东西,就把以前用过的东西整合了一下。统一网络结构外的东西(数据增广,预处理,优化器等)把 ResNet从76.1干到78.8,修改网络结构后从78.8干到82.0。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡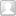 发表于 2025-3-2 21:15
发表于 2025-3-2 21:15


 提升卡
提升卡