金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
先导知识
前言
FAIR于近日提出的ConvNeXt[1]得到了广泛的关注,它引起关注的原因是它靠卷积结构便达到了ImageNet Top-1的准确率,与这两年来流行的使用Transformer[2]解决视觉问题的趋势背道而驰,让不少读者感叹“爷青回!”。再加上有何恺明,RBG,Yann LeCun的站台,很难不让人关注这篇文章。
ConvNeXt并没有特别复杂或者创新的结构,它的每一个网络细节都是已经在不止一个网络中被采用。而就是靠这些边角料的互相配合,却也达到了ImageNet Top-1的准确率。它涉及这些边角料的动机也非常简单:Transformer或者Swin-Transformer [3]怎么做,我也对应的调整,效果好就保留。当然这些边角料的摸索也是需要大量的实验数据支撑的,是一个耗时耗力耗资源的过程。通过对ConvNeXt的学习,我等调参侠不仅可以学习到诸多的炼丹经验,还可以一探其背后原理,在CNN和Transformer的大战中以内行的角度吃瓜。
论文:https://arxiv.org/abs/2201.03545
源码:https://github.com/facebookresearch/ConvNeXt
1. ConvNeXt的进化路径
图1概括了ConvNeXt的所有优化点,它从ResNet-50[4]或者ResNet-200出发,依次从宏观设计,深度可分离卷积(ResNeXt[5]),逆瓶颈层(MobileNet v2[6]),大卷积核,细节设计这五个角度依次借鉴Swin Transformer的思想,然后在ImageNet-1K上进行训练和评估,最终得到ConvNeXt的核心结构。
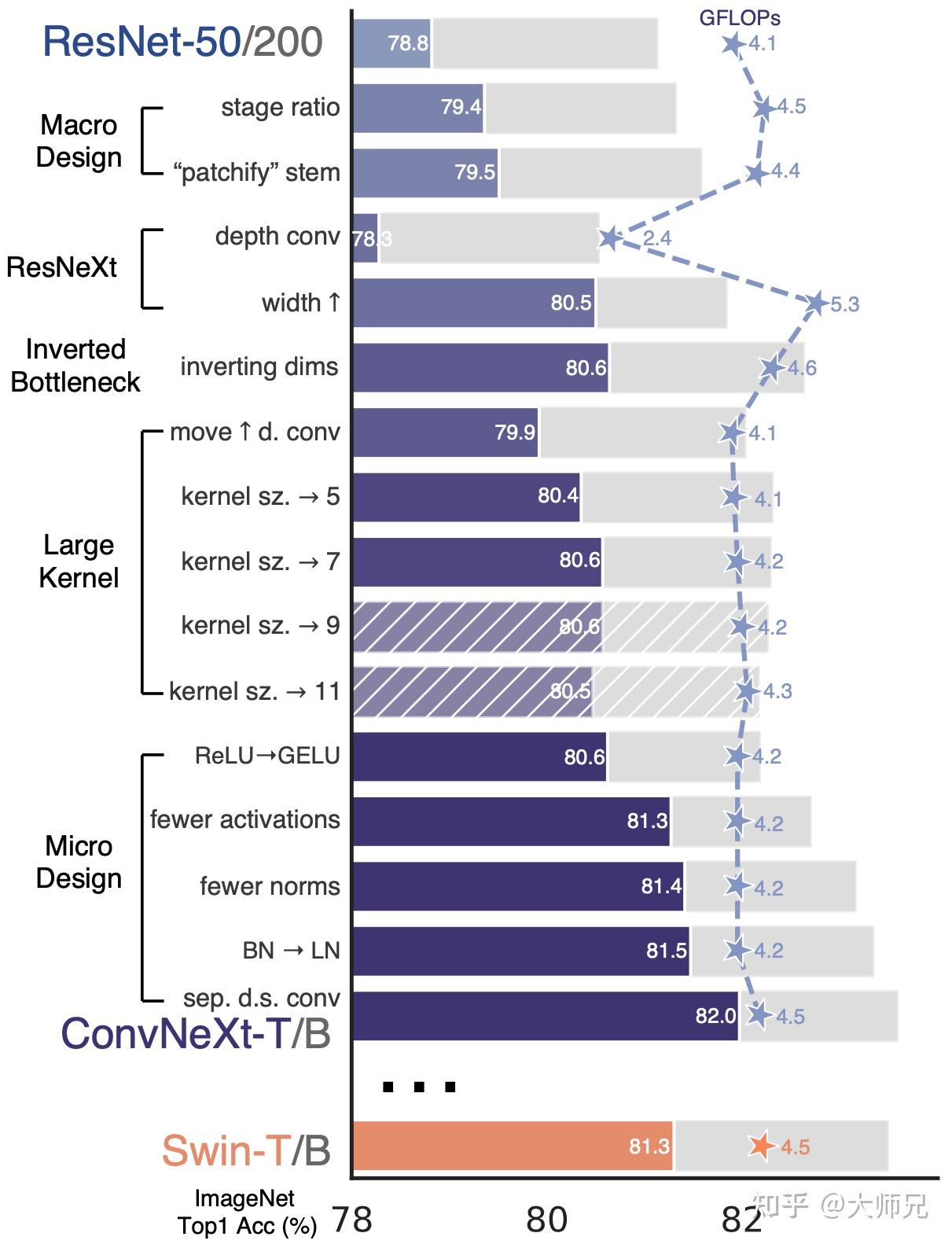
图1:ConvNeXt的网络结构优化策略
1.1 训练方式
随着深度学习在各个领域上的不断探索,残差网络锁采用的原始策略已经不能充分的压榨残差结构的性能,例如前不久的ResNet-timm[10] 就通过一系列训练trick将ResNet在ImageNet-1k的Top-1的准确率提升到80%+。在介绍ConvNeXt的结构优化之前,我们先简单介绍一下ConvNeXt的训练方法。我们知道ResNet-50在ImageNet-1k上最终的Top-1的准确率是76.1%,而图1中ResNet-50说的是78.8%,而这2.7%的准确率的提升正是依靠对训练策略的优化所达到的。
在ConvNeXt中,它的优化策略借鉴了Swin-Transformer。具体的优化策略包括:(1)将训练Epoch数从90增加到300;(2)优化器从SGD改为AdamW;(3)更复杂的数据扩充策略,包括Mixup,CutMix,RandAugment,Random Erasing等;(4)增加正则策略,例如随机深度[7],标签平滑[8],EMA[9]等。更具体的预训练和微调的超参数如图2。
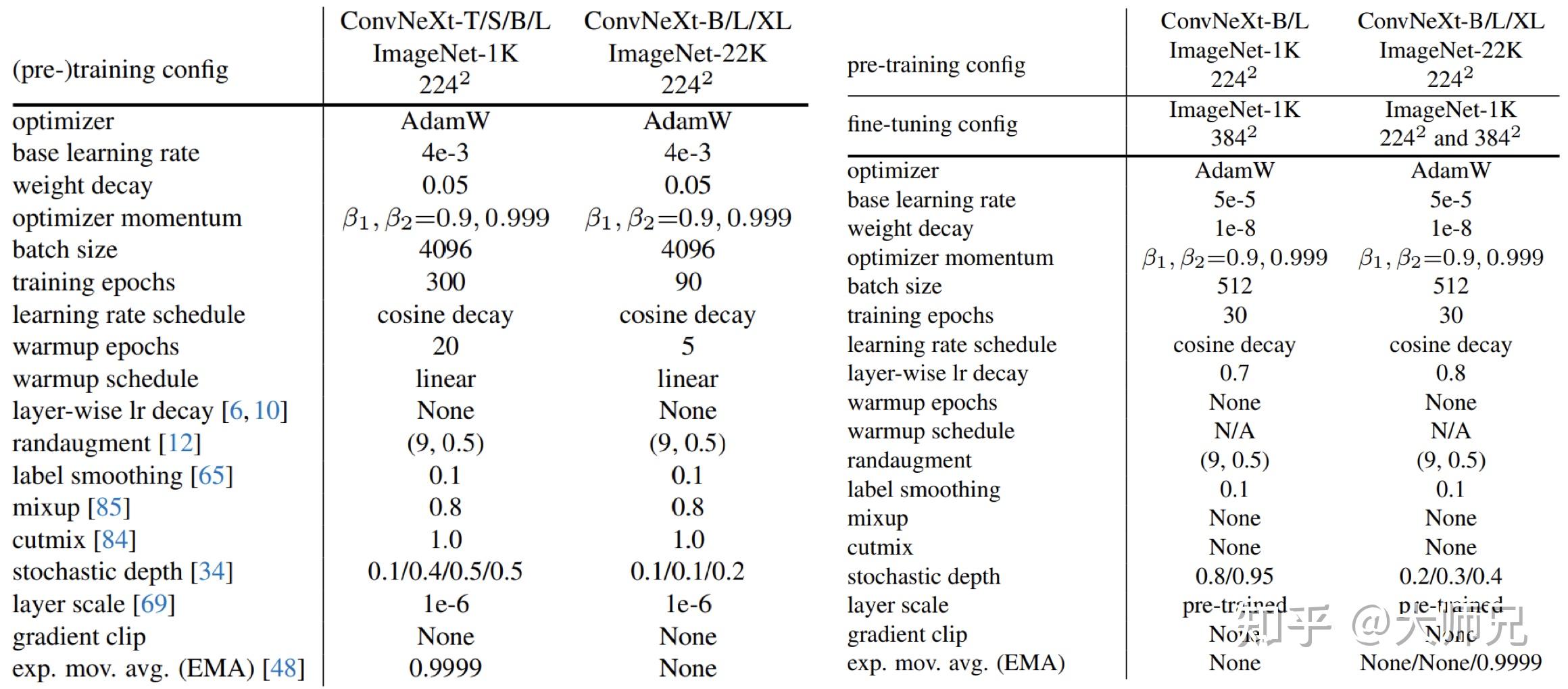
图2:ConvNeXt的训练参数
1.2 宏观设计
1.2.1 每个阶段的计算占比(Stage Ratio)
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将Feature Map降采样到不同的尺寸。在VGG中,每个网络块的网络层的数量基本是相同,但在之后的很多工作中,他们指出当深层的网络块层数更多时,模型的表现更好。例如,ResNet-50中共有4个不同的网络块,每个网络块又有若干个不同的基础层,一般是由卷积,BN等操作组成,它的每个网络块的层数是 (3,4,6,3) 。
在Swin-Transformer中,每个骨干网络被分成了4个不同的Stage,每个Stage又是由若干个Block组成,在Swin-Transformer中,这个Block的比例是 1:1:3:1 ,而对于更大的模型来说,这个比例是 1:1:9:1 。ConvNeXt的改进是将ResNet-50的每个Stage的block的比例调整到 1:1:3:1 ,最终得到的block数是 (3,3,9,3) 。从图1中可以看出这个改进将ResNet-50的准确率从78.8%提升至79.4%。注意这里模型的GFLOPs从4.1增加至4.5,这0.6%的准确率的提升也有一部分功劳要归功于模型参数量的增加。此外ConvNeXt还提供了更大的block数为 (3,3,27,3) 的模型。
1.2.2 Patchify Stem
对于ImageNet数据集,我们通常采用 224\times224 的输入尺寸,这个尺寸对于ViT等基于Transformer的模型来说是非常大的,它们通常使用一个步长为4,大小也为4的卷积将其尺寸降采样到 56\times56 。因为这个卷积的步长和大小是完全相同的,所以它又是一个无覆盖的卷积,或者叫Patchify(补丁化)的卷积。这一部分在Swin-Transformer中叫做stem层,它是位于输入之后的一个降采样层。
在ConvNeXt中,Stem层也是一个步长为4,大小也为4的卷积操作,这一操作将准确率从79.4%提升至79.5%,GFLOPs从4.5降到4.4%。也有人指出使用覆盖的卷积(例如步长为4,卷积核大小为7的卷积)能够获得更好的表现。
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)1.2.3 分组卷积
在轻量级模型中,我们介绍了深度可分离卷积,它们将 3 \times 3 卷积以通道为单位进行运算(深度卷积),然后再通过 1\times1 卷积进行通道融合(点卷积)。而ResNeXt是一个更折中的方案,它通过分组卷积(将通道分组,然后以组为单位进行卷积)的方式来提升模型的计算速度。与之类似的是,Swin-Tranformer的Self-Attention也是以通道为单位的运算单元,不同的是可分离卷积是可学习的卷积核,Self-Attention是根据数据动态计算的权值。
在ConvNeXt中,也引入了分组卷积的思想。它将 3\times3 卷积替换成了 3\times3 的分组卷积,这个操作将GFLOPs从4.4降到了2.4,但是它也将准确率从79.5%降到了78.3%。为了弥补准确率的下降,它将ResNet-50的基础通道数从64增加至96。这个操作将GFLOPs增加到了5.3,但是准确率提升到了80.5%。
1.2.3 逆瓶颈层
瓶颈层是一个中间小,两头大的结构,最早在残差网络中被使用。而在MobileNet v2中则使用了一个中间大,两头小的结构,他们认为这个结构能够有效的避免信息流失。之后的 Transformer本质也是一个逆瓶颈层的架构,在Transformer中,Self-Attention的隐层节点数是512,而中间的全连接的隐层节点数是2048。这里的ConvNeXt也是使用了逆瓶颈层的结构,如图3.(a)和图3.(b)所示。这个策略将准确率提升至85.6%,GFLOPs降低至4.6。
在后续的工作中,作者尝试了使用更大的卷积核。为了适应更大的卷积核,作者将卷积的图3.(b)的深度卷积向上移动了一层,如图3.(c)。此操作将准确率降低到了79.9%,但是GFLOPS也下降到了4.1%。
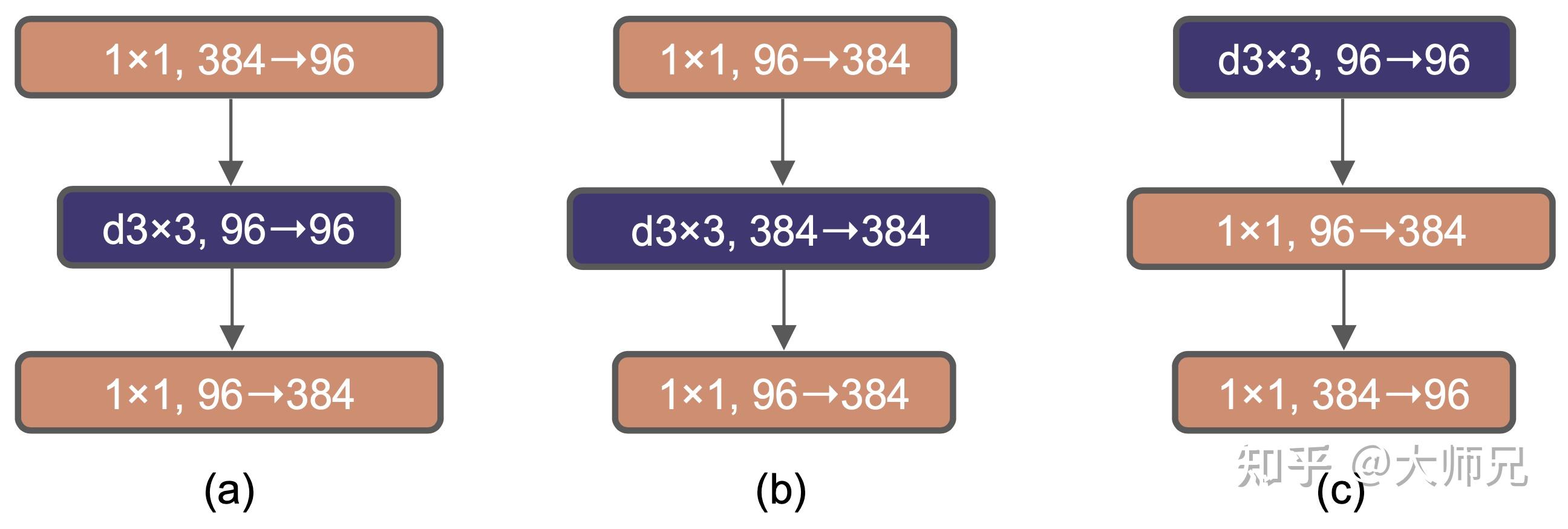
图3. (a) ResNeXt的瓶颈层架构,(b) ConvNeXt的逆瓶颈层架构,(c)ConvNeXt又将可分离卷积向上移动了一层
1.3 更大卷积核
大卷积核是一个比较古老的卷积运算参数,上次看见这些大卷积核还是在AlexNet,VGG等这些上古网络中。当时使用小卷积核替代大卷积核,一个重要的原因是一个大卷积核( 5\times5 卷积)和两层的小卷积核( 3\times3 卷积)在拥有相同感受野的情况下,表现是比两层小卷积核略差的。在Swin-Transformer中,它们使用的是 7\times7 自注意力窗口本质上也是一个大的计算窗口,因此这里作者也对大的卷积核重新进行了对照实验。
在ConvNeXt的实验中,它们尝试了 5\times5 , 7\times7 , 9\times9 和 11\times11 共4个不同尺寸的卷积操作。从图1的实验结果来看, 7\times7 卷积操作的效果最好。它将模型的准确率提升至80.6%,GFLOPs些许增加至4.2。并且从这个实验结果中可以看出,大卷积核对模型速度的影响并不很大,这可能是得益于当前深度学习框架以及硬件对大卷积核的支持更友好。
1.4 细节优化
1.4.1 ReLU替换为GELU
ReLU是比较早期的激活函数,近年来更多的模型选择使用GELU[11]作为激活函数,例如ConvNeXt要对齐的Swin Transformer。在ConvNeXt的实验中,GELU并没有提升模型的准确率和效率。但是为了对齐其它指标,ConvNeXt还是选择了GELU作为激活函数。
1.4.2 更少的激活函数
在以往的卷积网络中,我们倾向于为每一个卷积操作都添加一个激活函数,但Transformer使用了更少的激活函数,Transformer是由一个自注意力层和两个MLP组成,但它仅在一个MLP上使用了激活函数。
ConvNeXt也借鉴了Transformer的思想,它仅在两个 1\times1 卷积之间添加了一个GELU激活函数。实验结果表明这个操作将准确率从80.6%提升至81.3%。
1.4.3 更少的归一化层
Transformer也是一个归一化层使用的非常少的网络结构,因此在ConvNeXt中也使用了更少的归一化操作,它仅在第一个 1\times1 卷积之前添加了一个BN,而更多的归一化操作对模型效果提升并没有帮助。通过这个操作将模型的准确率提升至81.4%。
1.4.4 BN替换为LN
根据我们之前的经验,BN[12]经常被用在CNN中,而LN[13]通常是用来解决BN在样本量过少的时候归一化统计量偏差过大的问题的。也有实验结果表明,如果将残差网络中的BN直接替换为LN的话,模型的性能反而会下降。
但是在ConvNeXt中,因为之前作者做了若干个将卷积网络向Transformer的改进,因此这里也尝试了将ConvNeXt中的BN替换为LN,令人意外的是,LN在ConvNeXt中要比BN表现的好,它将模型的准确率提升至81.5%。
因为上述改进都是非常小的点的优化,对模型的速度影响并不大,因此ConvNeXt的GFLOPs维持在了4.2没变。上述的所有改进如下面代码片段所示。注意下面的代码中的 1\times1 卷积使用的是线性层来实现的。
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x1.4.5 拆分降采样层
在残差网络中,它通常使用的是步长为 2 的 3\times3 卷积或者 1\times1 卷积来进行降采样,这使得降采样层和其它层保持了基本相同的计算策略。但是Swin Transformer将降采样层从其它运算中剥离开来,即使用一个步长为2的 2\times2 卷积插入到不同的Stage之间。ConvNeXt也是采用了这个策略,而且在降采样前后各加入了一个LN,而且在全局均值池化之后也加入了一个LN,这些归一化用来保持模型的稳定性。这个策略将模型的准确率提升至82.0% 。
self.downsample_layers = nn.ModuleList()
# stem也可以看成下采样层,一起存到downsample_layers中,推理时通过index进行访问
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims, eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims, dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)最终,ConvNeXt的结构如图4.(b)所示,与之对应的是图4.(a)的残差网络。
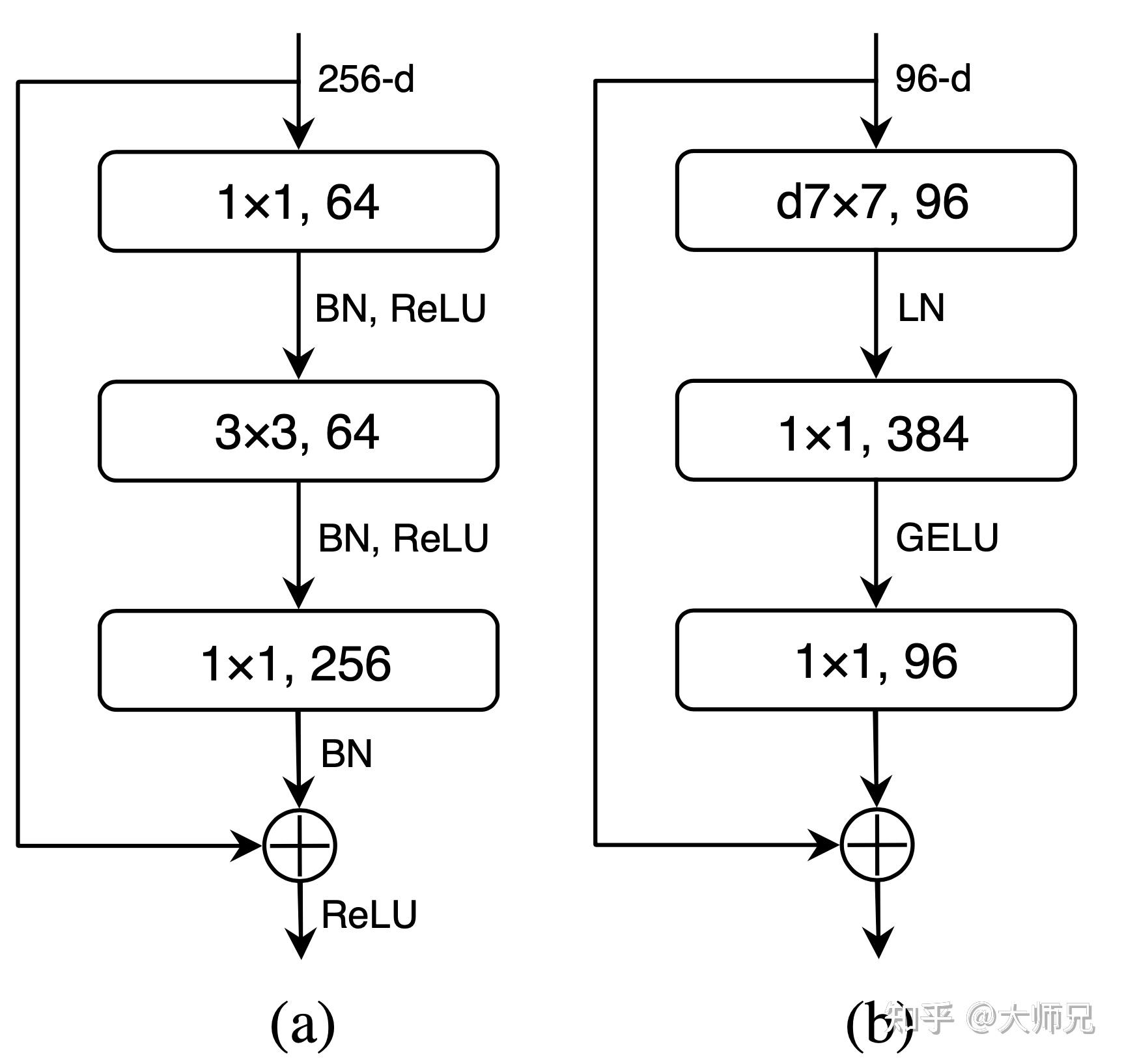
图4:(a)残差网络和(b)ConvNeXt
2. ConvNeXt的多种版本
ConvNeXt提供了多个参数尺度的模型,他们的参数结构和在ImageNet-1K的Top-1的准确率如表1。
| 网络结构 | 输入尺寸 | 通道数 | Block数 | 准确率 | | ConvNeXt-T | 224 | 96, 192, 384, 768 | 3, 3, 9, 3 | 82.1% | | ConvNeXt-S | 224 | 96, 192, 384, 768 | 3, 3, 27, 3 | 83.1% | | ConvNeXt-B | 384 | 128, 256, 512, 1024 | 3, 3, 27, 3 | 85.1% | | ConvNeXt-L | 384 | 192, 384, 768, 1536 | 3, 3, 27, 3 | 85.5% | | ConvNeXt-XL | 384 | 256, 512, 1024, 2048 | 3, 3, 27, 3 | 87.8% |
表1:不同尺度的ConvNeXt的超参数值以及准确率
除了这里介绍的ConvNeXt,论文中还设计了一个和ViT[14]结构类似的Isotropic ConvNeXt,即采用同质结构的ConvNeXt:即先通过一个patch embedding层得到输入patch的embedding,然后送入参数共享的网络中进行特征学习。从效果上来看,Isotropic的效果和ViT基本一样,这说明了Transformer在视觉任务上并没有明显的结构优势。
3. 总结
将Transformer移植到计算机视觉领域是一个由结果推原理的一个计算流程,并没有什么资料说明Self-Attention是在原理上比卷积更适用于图像任务。我们也没必要过分神话Self-Attention,它本质上还是矩阵的密集计算,它的提出有很大的功劳是得益于计算性能的提升。在没有充分理论支持的情况下,自注意力注定只是计算机视觉方向的一个过客。但是在此时此刻,Transformer能在计算机视觉掀起多大的波澜,还是要看硬件性能的提升效率,新范式的提出时间,以及卷积的反抗。
这里介绍的ConvNeXt就是CNN的一个很好的反击,它在保持CNN结构的基础之上,通过“抄袭”Swin Transformer等方法的调参技巧,证明了Transformer在视觉领域上的突出表现并不是Transformer在理论上更适合图像数据,而只是近年来的诸多的提升准确率的小Trick带来的附加作用,就像前不久的ResNet-Timm[10],它也能在仅仅修改调参技巧也能把残差网络的准确率提升到80%+。
我不想就此否定Transformer在视觉方向的突出贡献,它将Transformer在NLP领域的进展带来的经验技巧融入到CV领域,对CV领域的发展也是非常具有促进意义的,而且对目前的多模态深度学习的发展也非常重要。我们也期待将来有一天,我们能找到一个比CNN和Transformer都更适合于图像任务的结构范式。
Reference
[1] Liu, Zhuang, et al. "A ConvNet for the 2020s." arXiv preprint arXiv:2201.03545 (2022).
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[3] Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021).
[4] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[5] Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[6] Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[7] Huang, Gao, et al. "Deep networks with stochastic depth." European conference on computer vision. Springer, Cham, 2016.
[8] Müller, Rafael, Simon Kornblith, and Geoffrey Hinton. "When does label smoothing help?." arXiv preprint arXiv:1906.02629 (2019).
[9] Polyak, Boris T., and Anatoli B. Juditsky. "Acceleration of stochastic approximation by averaging." SIAM journal on control and optimization 30.4 (1992): 838-855.
[10] Wightman, Ross, Hugo Touvron, and Hervé Jégou. "Resnet strikes back: An improved training procedure in timm." arXiv preprint arXiv:2110.00476 (2021).
[11] Hendrycks, Dan, and Kevin Gimpel. "Gaussian error linear units (gelus)." arXiv preprint arXiv:1606.08415 (2016).
[12] Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." International conference on machine learning. PMLR, 2015.
[13] Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016).
[14] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
原文地址:https://zhuanlan.zhihu.com/p/459163188 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-2-27 05:19
发表于 2025-2-27 05:19
 提升卡
提升卡


