金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
Planner
在具体介绍之前,由于Dynamo 更新了planner, 在这个地方也给大家解释说明一下。这个 planner 主要的作用是实时来根据系统负载来动态扩缩容,通过 Prefill 队列大小以及 kv_load 负载来控制扩缩容的策略。
具体是调用 Circus 来监控和控制进程,通过 add_component 和 remove_component来从状态文件加载当前的系统配置,然后构建对应的命令来执行资源更新。另外 Planner还设置了一些保护机制,例如采用 blocking 的方式来扩缩容,每次只增加或减少一个工作节点,新增 decoding 节点之后的 3 个调整周期之内不变化等等。 具体的细节大家可以查阅 Planner 的源码,都不是特别复杂。不过现在 Planner 也是在持续更新,目前只支持 vLLM 的backend。
现在我们接着上个系列来讲解Dynamo 的架构和实现,本文会着重介绍 Rust 部分对于 KV cache 的处理,对于前文不清楚的可以移步:
PD 分离系列 - NVIDIA Dynamo 代码原理解析 (一) - SuriWu.NTS的文章 - 知乎
SuriWu.NTS:PD 分离系列 - NVIDIA Dynamo 代码原理解析 (一)
其实在 PD 分离的架构中,比较关键的就是 P和 D 的调度,以及 KV cache 的传输和储存。本文会主要分析 Rust 代码中 KV_Router 和 KV部分。
KV_Router
/dynamo/lib/llm/src/kv_router.rs 下的 KV Router 的主要功能实际上和前文提到的是类似的,但是会多出来一些KV cache 的发布和订阅操作。下面的 scheduler 是具体执行 KV router 调度决策的核心代码,其实 KvScheduler::start里面部分的实现和之前 python 的版本是一致的,都采用了相似的计算逻辑,感兴趣的可以到dynamo/lib/llm/src/kv_router/scheduler.rs下看一下WorkerSelector的具体代码。
pub const KV_EVENT_SUBJECT: &str = "kv_events";
let metrics_aggregator =
KvMetricsAggregator::new(component.clone(), cancellation_token.clone()).await;
let indexer = KvIndexer::new(cancellation_token.clone(), block_size);
let scheduler = KvScheduler::start(
component.namespace().clone(),
block_size,
metrics_aggregator.endpoints_watcher(),
selector,
)
.await?;
// [gluo TODO] try subscribe_with_type::<RouterEvent>,
// error checking below will be different.
let mut kv_events_rx = component.subscribe(KV_EVENT_SUBJECT).await?;
let kv_events_tx = indexer.event_sender();
我们着重介绍一下 Dynamo 里面的 publish 和 subscribe 机制(即发布和订阅)。其中会涉及到RouterEvent,KvCacheEvent,KvCacheEventData 等,这种设计能够跟踪分布式环境中的 KV 缓存状态,并支持高效的路由决策和缓存管理。我们现在来跟着整个调用的链路来过一遍整个Event 的流程:
假如我们有1 个 KvRouter,2 个工作节点 worker1 和 worker2
1. 用户发送一个请求 RouterRequest,包含token 序列[100,200,300,400]
pub struct RouterRequest {
pub tokens: Vec<Token>,
}
2. KvRouter接收到RouterRequest之后,根据 token 来计算 block_hash
let local_block_hashes: Vec<LocalBlockHash> = tokio::task::spawn_blocking(move || {
Tokens::compute_block_hash(&request.tokens, block_size)
.into_iter()
.map(LocalBlockHash)
.collect()
})
3. KvRouter 调用 KVIndexer 来查找匹配的工作节点
// KvRouter::generate
let overlap_scores = self.indexer.find_matches(local_block_hashes).await?;
4. KvRouter调用 KvScheduler 来选择工作节点
let worker_id = self.scheduler.schedule(overlap_scores, isl_tokens).await?;5. 由于是第一次调用,没有匹配信息,Scheduler 会根据负载和资源使用情况选择 worker,假如选择了 worker1
let response = RouterResponse { worker_id };
6. 将请求发送到 worker1 ,在其中处理请求,创建并发布缓存 Event到 KV_EVENT_SUBJECT
def enqueue_stored_event(self, parent: Optional[PrefixCachingBlock],
block: PrefixCachingBlock):
token_ids_arr = (ctypes.c_uint32 *
len(block.token_ids))(*block.token_ids)
num_block_tokens = (ctypes.c_size_t * 1)(len(block.token_ids))
block_hash = (ctypes.c_uint64 * 1)(block.content_hash)
parent_hash = ((ctypes.c_uint64 * 1)(parent.content_hash)
if parent is not None else None)
# Publish the event
result = self.lib.dynamo_kv_event_publish_stored(
self.event_id_counter, # uint64_t event_id
token_ids_arr, # const uint32_t *token_ids
num_block_tokens, # const uintptr_t *num_block_tokens
block_hash, # const uint64_t *block_ids
1, # uintptr_t num_blocks
parent_hash, # const uint64_t *parent_hash
0, # uint64_t lora_id
)
let kv_cache_event = KvCacheEvent {
event_id: 1,
data: KvCacheEventData::Stored(KvCacheStoreData {
parent_hash: None,
blocks: vec![KvCacheStoredBlockData {
block_hash: ExternalSequenceBlockHash(0),
tokens_hash: LocalBlockHash(13226331709069118873),
}],
}),
};
7. KvRouter 订阅 KV_EVENT_SUBJECT接受缓存事件,反序列化 RouterEvent并转发给 KvIndexer 处理,更新 RadixTree
let event: RouterEvent = match serde_json::from_slice(&event.payload) {
Ok(event) => {
tracing::debug!("received kv event: {:?}", event);
event
}
Err(e) => {
tracing::warn!("Failed to deserialize RouterEvent: {:?}", e);
// Choosing warn and continue to process other events from other workers
// A bad event likely signals a problem with a worker, but potentially other workers are still healthy
continue;
}
};
if let Err(e) = kv_events_tx.send(event).await {
tracing::trace!("failed to send kv event to indexer; shutting down: {:?}", e);
}
}
});
8. 后续请求会按照上述流程,计算 hash 之后查找匹配的 Worker ID,执行上述流程循环。整体的架构图如下。
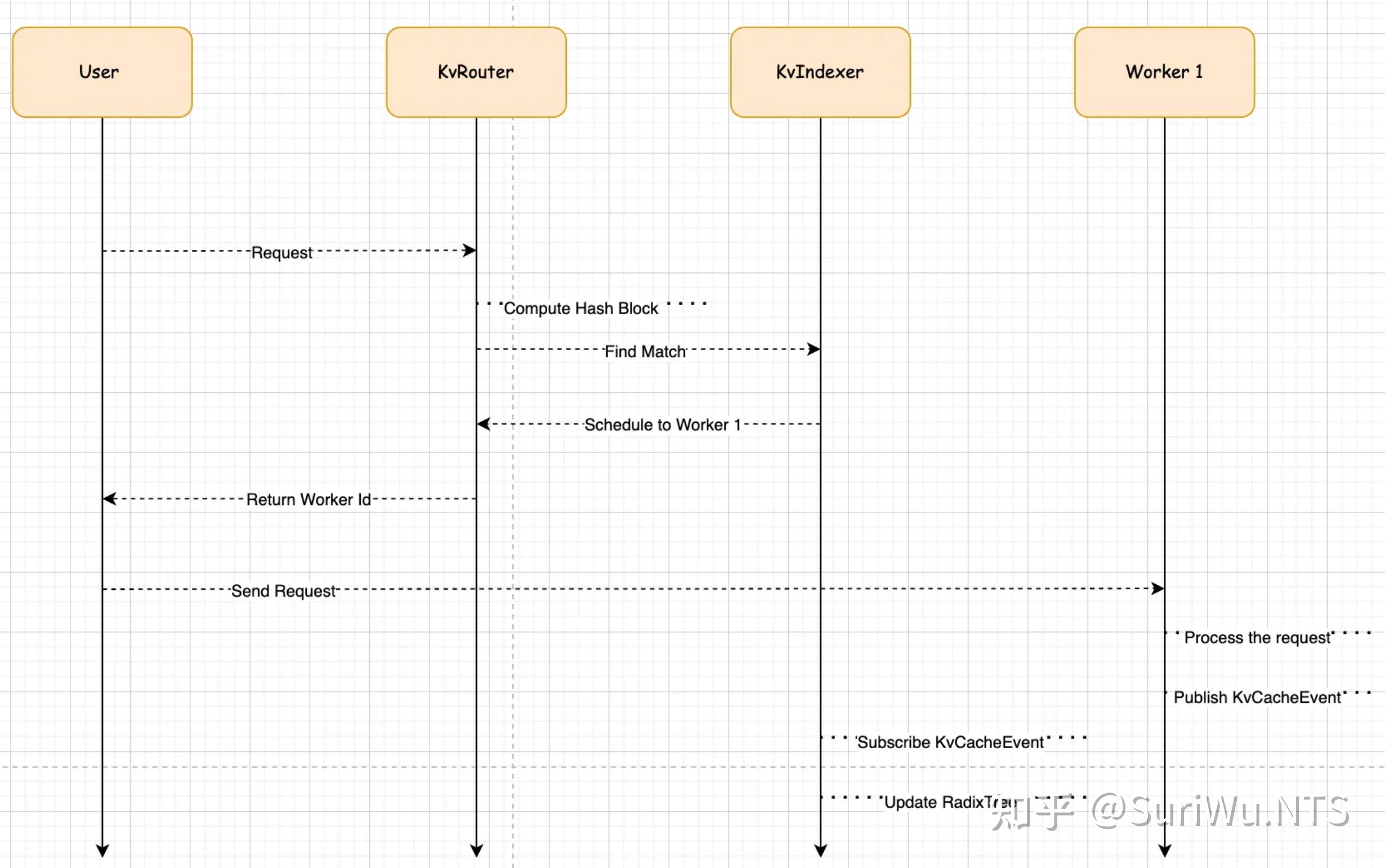
到这个地方大家可以看到,RadixTree 是 KV Router 的一个比较核心的组件,作为 KvIndexer 的一部分,维护 token block hash 和 woker 之间的映射,通过事件机制来与分布式的节点保持同步。这样中心化索引的设计简化了 Router 的决策逻辑,并且 Worker 节点不需要知道 RadixTree 的存在,只需要专注计算任务,发布缓存事件即可。
下面这一部分会涉及到 kv 的复制,管理,保存等等,也是 dynamo 里面关于 kv 的核心组件。我会按照 Rust 里的代码结构来给大家逐一介绍理解。
KV Layers
KV layers 实现了 KV 缓存的层级结构、存储管理和数据传输功能。这个文件构建了整个 KV 缓存系统的基础架构
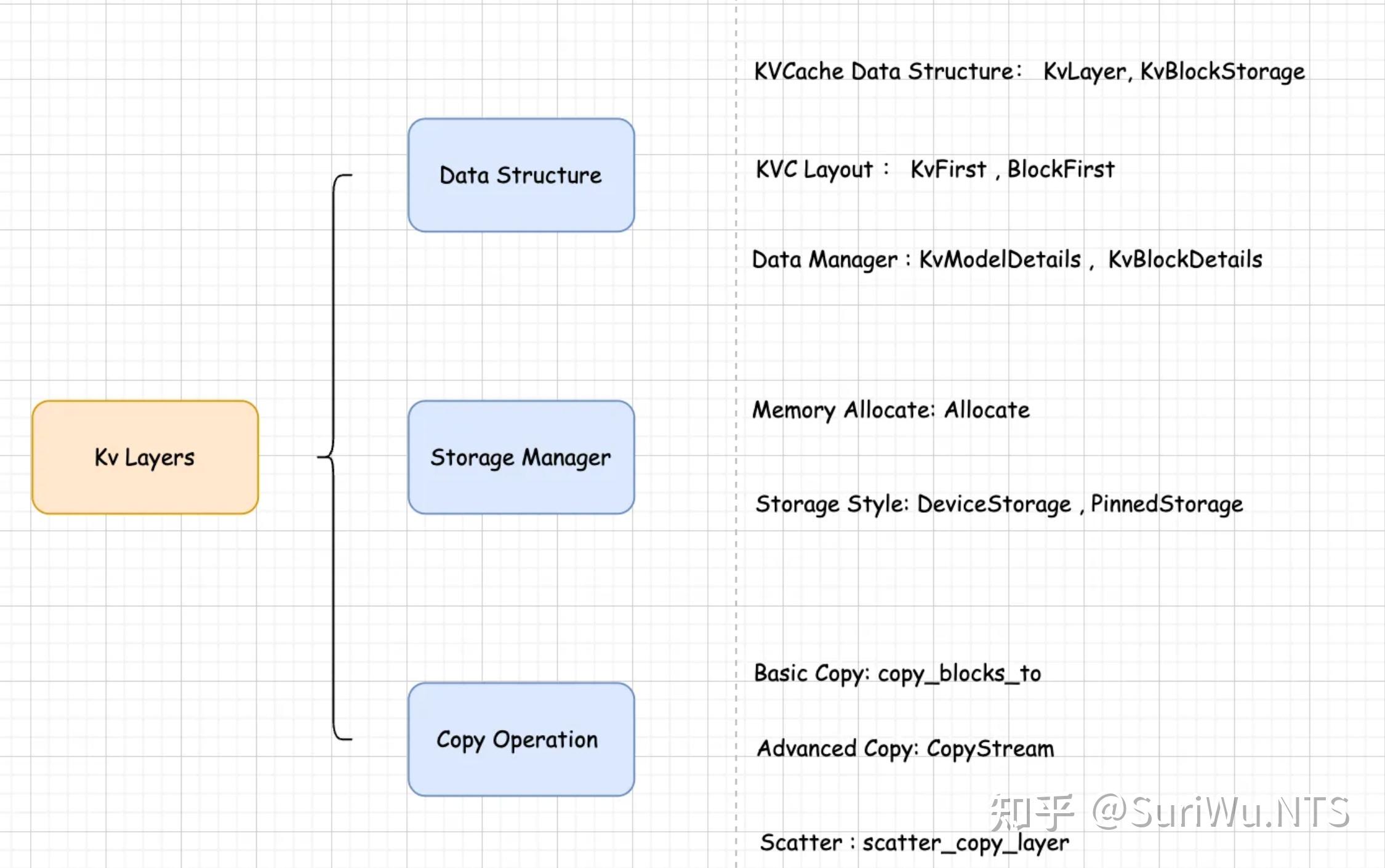
- 初始化 KVCache 并分配内存(在此之前会初始化Layers info来确定 KV缓存的大小),包括模型的结构参数以及 KVCache 的Layout 类型和 block 大小。接着会在 GPU 和 CPU 上分配储存,GPU 用来访问处理,CPU可以用来储存不常用的 KVCache
let model_details = KvModelDetailsBuilder::default()
.number_of_layers(number_of_layers)
.number_of_heads(number_of_heads)
.head_size(head_size)
.dtype(DType::F32) // Use F32 for easier validation
.build()?;
let block_details = KvBlockDetailsBuilder::default()
.layout(layout.clone())
.block_size(block_size)
.tp_size(1)
.tp_rank(0)
.model_details(model_details)
.build()?;
// Create the storage blocks
let h_blocks = KvBlockStorage::allocate(
number_of_cpu_blocks,
block_details.clone(),
StorageType::Pinned,
)?;
let d_blocks = KvBlockStorage::allocate(
number_of_gpu_blocks,
block_details.clone(),
StorageType::Device(device.clone()),
)?;
2. 这里可以实现卸载部分指定 KVCache block 到 CPU 上,实现灵活的数据搬运策略。copy_blocks_to是一个同步阻塞操作,复杂简单场景的数据搬运
// 从 GPU 复制特定块到 CPU
let gpu_layer = gpu_blocks.layer(0)?; // 获取GPU存储的第0层 (read only)
let mut cpu_layer = cpu_blocks.layer_mut(0)?; // 获取CPU存储的第0层(read or write)
gpu_layer.copy_blocks_to(&[0, 1, 2], &mut cpu_layer, &[0, 1, 2])?;
3. 创建 h2d 和 d2h 的 BlockMap,包括源数据以及目标数据的 layer pointer 相关信息。然后创建 CopyStream,并设置对应的 layer pointer 信息。指定传输所有 Blocks,然后调用trigger_all_layers触发所有layer 的异步传输,如果需要的话用sync_stream来等待传输结束。这样的设计允许计算和传输 overlap,来提升整体的吞吐。
let h2d_block_map = CopyStreamBlockMap::new(&h_blocks, &d_blocks).unwrap();
let d2h_block_map = CopyStreamBlockMap::new(&d_blocks, &h_blocks).unwrap();
let mut copy_stream = CopyStream::new(number_of_layers, number_of_gpu_blocks).unwrap();
// block list 0..64 as i32
let mut block_list: Vec<i32> = (0..number_of_gpu_blocks).map(|x| x as i32).collect();
block_list.shuffle(&mut rng);
let src_block_ids = block_list.clone();
block_list.shuffle(&mut rng);
let dst_block_ids = block_list.clone();
// Select the appropriate block map based on direction
if is_h2d {
copy_stream.prepare_block_map(h2d_block_map).unwrap();
} else {
copy_stream.prepare_block_map(d2h_block_map).unwrap();
}
copy_stream
.prepare_block_ids(src_block_ids, dst_block_ids)
.unwrap();
let timer = Instant::now();
copy_stream.trigger_all_layers().unwrap();
copy_stream.sync_stream().unwrap();
for _ in 0..iterations {
copy_stream.trigger_all_layers().unwrap();
copy_stream.reuse().unwrap();
}
copy_stream.sync_stream().unwrap();
4. 另外 Dynamo 提供了一个Tensor 重排的操作,用来重新组织Tensor 维度
copy_stream.scatter_copy_layer(
0,
&dims,
elem_size,
block_dim_idx,
src_tp_size,
dst_tp_size,
)?;
KV Managers/Reserved/Reuse
Kv Managers的结构比较简单,主要是通过KvStorageManager来定义AvailableBlocks,inflight_blocks (ReservedBlocks)以及 block_size,从而管理 GPU 或 CPU 里面的 KV Block 的分配和重用。

- 当新的推理请求到来时,首先为输入的 tokens 序列准备 KV cache 缓存,将 tokens 转化为固定大小的 block,然后尝试匹配inflight_blocks。
let seq = tokens.into_sequence(self.block_size);
let (blocks, tail_block) = seq.into_parts();
log::debug!(
"request translates to {} blocks; remaining tokens: {}",
blocks.len(),
tail_block.tokens().len()
);
// first match blocks to inflight blocks
let mut inflight_blocks = self.inflight_blocks.match_token_blocks(&blocks)?;
log::debug!("matched {} inflight blocks", inflight_blocks.len());
2. 对于没有匹配到的 block,尝试从 available_block 中去匹配,将匹配到的 block 注册为inflight_blocks
let unmatched_blocks = &blocks[inflight_blocks.len()..];
let unmatched_hashes = unmatched_blocks
.iter()
.map(|b| b.sequence_hash())
.collect::<Vec<_>>();
// match the remaining blocks to freed gpu blocks (available_blocks)
let unregistered_blocks = self.available_blocks.match_blocks(unmatched_hashes).await?;
log::debug!("matched {} freed blocks", unregistered_blocks.len());
// the blocks from the freed blocks pool must be registered as inflight blocks
// todo - we might have to register the list of unregistered blocks as a single transaction
for block in unregistered_blocks {
inflight_blocks.push(self.inflight_blocks.register(block)?);
}
3. 对于上述操作中没有匹配的Blocks,需要分配新的储存空间,从可用池中获取足够数量的块,将未匹配的 tokens 和可用Blocks 关联。
let mut blocks_to_reuse = self
.available_blocks
.take_blocks(remaining_blocks.len() as u32 + 1)
.await?;
if blocks_to_reuse.len() != remaining_blocks.len() + 1 {
raise!(
"expected {} blocks, got {}",
remaining_blocks.len() + 1,
blocks_to_reuse.len()
);
}
// update the blocks_to_reuse with the token block from remaining_blocks
let complete_prefill_blocks: Vec<UniqueBlock> = remaining_blocks
.into_iter()
.map(|b| {
let mut block = blocks_to_reuse.pop().unwrap();
block.update_token_block(b);
block
})
.collect();
assert_eq!(blocks_to_reuse.len(), 1);
let tail_kv_block = blocks_to_reuse.pop().unwrap();
KV Storage
该部分代码主要实现了一个底层的内存管理组件,提供高效灵活的方案。通过固定内存、张量视图、异步传输的组合,简化了相对复杂的内存管理任务,使上层代码能够专注于模型推理逻辑。它解决了例如跨设备内存管理,多维数据操作,高性能数据传输等等问题。 接下来会结合 Rust 中给出的样例来展示一下 KV Storage 的核心功能。
- 首先创建一个 cudaContext 上下文,绑定 cudaStream。然后创建一个固定大小的 pinned 内存块,以及引用该内存块的 Tensor View 。在避免额外内存复制的同时,可以按照行列 index 简单的访问数据。
// Initialize CUDA
let context = CudaContext::new(0).unwrap();
let stream = context.default_stream();
// Create a host tensor with f32 elements (6 elements)
let pinned_storage = OwnedStorage::create_pinned_array(6 * 4).unwrap();
// Create a host tensor view
let shape = [2, 3];
let mut host_view = TensorView::<_, 2>::new(&pinned_storage, shape, 4).unwrap();
2. 重新定义一个包含 6 个 f32 值的数组,按照行优先的顺序填入 Tensor View。并在 GPU 上创建一个内存块,以及Tensor View。然后将数据从 CPU 传输到 GPU
// Set some values
let values = [1.0f32, 2.0, 3.0, 4.0, 5.0, 6.0];
for i in 0..2 {
for j in 0..3 {
host_view
.set_element::<f32>(&[i, j], values[i * 3 + j])
.unwrap();
}
}
// Create a device tensor
let device_storage = OwnedStorage::create_device_array(6 * 4, context.clone()).unwrap();
let mut device_view = TensorView::<_, 2>::new(&device_storage, shape, 4).unwrap();
// Copy from host to device using h2d method
host_view.h2d(&mut device_view, &stream).unwrap();
3. 创建另一个固定内存块和 Tensor View,用于接收从 GPU 返回的数据流。这里分离输入和输出的内存,防止堵塞竞争。
// Create another host tensor for receiving data back
let pinned_storage2 = OwnedStorage::create_pinned_array(6 * 4).unwrap();
let mut host_view2 = TensorView::<_, 2>::new(&pinned_storage2, shape, 4).unwrap();
// Copy from device to host using d2h method
device_view.d2h(&mut host_view2, &stream).unwrap();
stream.synchronize().unwrap();4. 检查确保整个传输过程保持数据的完整性
// Verify the data was correctly transferred
for i in 0..2 {
for j in 0..3 {
assert_eq!(
host_view2.get_element::<f32>(&[i, j]).unwrap(),
values[i * 3 + j]
);
}
}
原文地址:https://zhuanlan.zhihu.com/p/1911201145034110047 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-6-1 16:04
发表于 2025-6-1 16:04
 提升卡
提升卡


